
Outages can cost your organization up to $25,000 per minute. AIOps and automation can simplify, enhance, and shorten incident triage, leading to faster MTTR.
Blog
IT outages cost $14,056 per minute on average. What’s driving the increased costs? How can you use AIOps to reduce their frequency, duration, and impact?

BigPanda 24 brought together ITOps leaders from across industries to discuss the future of AIOps and IT operations. CEO Assaf Resnick shares his thoughts.
Reduce manual incident investigation, identify actionable insights, and speed resolution using relevant historical data from similar incidents.

Improve uptime and efficiency. With full-context IT operations management, you get the big picture of incidents every time, from every angle.
The BigPanda AI-powered copilot is the first to leverage all sources of human-generated, institutional knowledge for AI-powered incident response.

Discover AIOps: Explore use cases, benefits, and tips on applying artificial intelligence to enhance efficiency and insights in your ITOps.

Learn the critical steps to achieving full-context ops that transform alerts into actionable insights and maximize IT efficiency and system performance.
Full-context operations provide the data, insights, and processes to make every stage of incident management faster, more consistent, and sustainable.

Discover the power of AIOps in transforming IT infrastructure monitoring into a proactive strategy.

IT infrastructure monitoring is a systematic process of observing, collecting data, and analyzing the performance, availability, and health of IT components.

Revolutionize IT service assurance by using AI to enhance operational performance, predict issues, and automate responses.
Elevate efficiency using advanced IT monitoring software and AIOps. Intelligent insights ensure seamless IT operations for sustained business success.

Discover how to set up BigPanda Open Integration Manager, alert normalization, and mapping enrichment to maximize your alert management.

Use AIOps to help financial services ITOps teams tackle common challenges and ensure the availability of always-on financial solutions.

Discover the power of self-healing IT. Learn how to overcome IT automation challenges to automate issue resolution, reduce downtime, and boost reliability with BigPanda and Red Hat Ansible.
Discover how to improve your ITIL incident management for swift issue resolution, minimal downtime, and continuous service improvement.

Gain insights into IT discovery, from its key components to its process so you can better manage complex tech environments.

Learn the strategies and steps to improving your alert payload. See how better alert data handling helps to improve your AIOps alert correlation.

Discover how ServiceNow AIOps uses artificial intelligence and transforms incident management for smarter IT operations.

Don’t let monitoring anomaly detection cause you stress. Learn how your AIOps can help speed incident resolution with observability anomaly detection.

Our AIOps predictions focus on what’s next with generative AI, integration, automation, incident management, job roles, and market trends.

Discover BigPanda CTO Oded Kedem. Read Oded’s story, his take on the future of the AIOps industry and automation, and advice for future CTOs.

Learn how the BigPanda Root Cause Changes feature optimizes incident management by linking incidents with relevant changes to reduce resolution time greatly.

BigPanda University is a self-paced learning hub offering hands-on experience, a comprehensive curriculum, and certifications for peak AIOps proficiency.
Explore strategies for optimizing cloud infrastructure management, balancing observability and monitoring, cost, and performance for peak efficiency.

Improve your organization’s incident response capabilities with incident management software. Learn how to find the ideal solution for your needs.

From events to alerts to incidents: Use this simple guide to navigate often misunderstood IT operations terminology.

Explore the features and benefits of a multi-cloud management platform for efficient and centralized control over diverse cloud services.

Discover the new BigPanda Unified Console with timeline views, data exports, AI insights, collaboration, incident tags and environments, and UI.

Application monitoring is indispensable to safeguard against disruptions and enhance user experience for modern organizations.
BigPanda’s Conor Castronovo, head of analyst relations, shares his findings from the Gartner IOCS conferences in London and Las Vegas.

Explore ServiceNow Incident Management: its importance, features, and benefits. Plus, learn how Autodesk reduced incidents by 69%.

Save money and prevent incidents from escalating into outages. Learn how to automate incident response with BigPanda.

Explore how incident management KPIs and metrics monitor and track ITOps performance. Discover actionable insights to improve your KPIs.

Discover how to begin your IT operations automation. Learn how to streamline workflows and tasks, reducing costs and improving operational efficiency.

Explore the significance of MTTR — mean time to resolution. Understand its impact on ITOps efficiency, service availability, and operational success.

Event analytics help streamline operations, detect issues, and optimize system performance to enhance efficiency. See how IHG and Zayo are using it.

Curious about mean time to detect? Learn how this KPI can help you proactively improve incident management and lower MTTR.
Discover what IT incident tracking is and why it matters. Gain strategies to select the right tools and improve system reliability.

Connect with BigPanda Gartner at IOCS 2023. Hear from our customers, meet our team, and learn how to get more value from your data with our AIOPs platform.

Ensure reliable ITOps with effective IT alert management. Discover how to implement and improve alert management for business continuity.
Discover what ServiceNow’s change management does, and how AIOps supports fast-paced IT with more insights for seamless change management.

Learn the basics of the PagerDuty incident response platform and how it integrates seamlessly with BigPanda for efficient IT operations.

Unlock IT efficiency with BigPanda Unified Analytics. See how to get end-to-end visibility, explore process improvement, and showcase value.

Discover the essentials of the observability tool landscape. Learn how to tame its complexity to improve IT system monitoring and cost efficiency.

Explore observability tool consolidation. Learn how AIOps streamlines tool usage, improves data, and reduces tool costs for IT systems.

Accelerate and automate incident response actions with Red Hat® Ansible® Automation Platform to focus on high-impact work.

Discover why ITOps needs intelligent alerts for efficiency and stability. Learn how applying AI/ML to alerts means smarter IT management.

Tool rationalization is hard for organizations with tool sprawl. Learn how BigPanda gives you a head start to understand your tools’ impact.

Discover ServiceNow IT Operations Management. Learn how ITOM enhances operational efficiency, its functionalities, and how to optimize it with AIOps.

Uncover how AIOps can enhance your observability tools by automating tasks, streamlining alerts, and speeding up incident resolution.

Discover the importance of IT incident management, its five-step process, and how AIOps can optimize IT event response.

Explore why perfect observability strategy is a myth and how AIOps can revolutionize monitoring for better insights and efficiency.

Explore how ServiceNow’s CMDB functions and discover the transformative power of AIOps in modernizing IT service management.

Learn how AI-powered event correlation can improve IT operations, how it works, how to choose a system. Get a free downloadable scorecard.

Explore how AIOps use cases help improve technical, operational, and business processes and outcomes.

Learn how IT Operations Analytics improve system reliability and availability. Become proactive with integrated and unified data. See use cases and KPIs.

Learn how AIOps enhances cloud observability, monitoring, and visibility for peak application performance.

AIOps platforms bridge the complexities of modern IT environments and the need for streamlined, effective incident management.

Explore AIOps’ impact on CMDB modernization and business outcomes. Unlock greater IT accuracy and insights with AIOps and CMDBs.
DevOps practices in software development have revolutionized the way updates are released. However, many companies entrenched in ITIL practices find it challenging to seamlessly integrate with the DevOps practice of Continuous Integration and Continuous Delivery/Deployment (CI/CD). This is because ITIL focuses on stability, which suits older systems, while DevOps is ideal for modern setups with […]

How does MTBF predict system reliability and uptime? Learn how it relates to MTTR and how to maximize it for seamless operations.

IT leaders are thrilled about the potential of Generative AI for IT Operations. But they also want to know how it works, why it works, and what it will do for them before taking the leap and adopting this new technology. Allow me to share my perspective on the hype and the truth behind generative […]

Finding the root causes of IT anomalies can be challenging, but the rewards are worth it. By identifying the root cause or causes of an incident or critical failure, response teams can resolve incidents faster and determine the best steps to avoid having them recur. This can drive down both the frequency of service interruptions […]

Learn how root-cause analysis and automation can help fix root causes, improve processes, and detect issues early.

Today, the majority of organizations operate under a hybrid cloud structure. Due to this, operations are consistently met with daily infrastructure and software changes and updates, which are also the primary cause of incidents and outages. Long gone are the days when a tech stack could be represented by a single dependency model. Microservices, CI/CD, […]

How BigPanda’s customer education resources can help your organization navigate change through the AI Revolution.

Discover what’s driving the analyst hype behind BigPanda’s AIOps innovations.
Transetyx quickly configured six standard monitoring integrations for a 96% noise reduction.

CEO Assaf Resnick explains why Dell’s acquisition of Moogsoft is proof of the ITOps AI revolution.

Discover how Datadog and BigPanda make observability and AIOps platforms function better for developer teams.

Deliver greater situational AIOps awareness at a lower cost with the combined impact of BigPanda and Cribl.
IT response teams find themselves battling against an overwhelming onslaught of incidents. Frustratingly long response times, challenges with prioritization, and the relentless pursuit of root cause are formidable adversaries that test even the most skilled teams. I remember customers’ electrifying anticipation with AI and automation a decade ago. They hoped AI could be used to […]

BigPanda’s experts share their cost optimization best practices. Discover how strategic IT cost optimization can reduce spend for software licensing, alert noise, ticket creation, and more.
Discover how applying AIOps to observability revolutionizes source monitoring at every stage.

BigPanda transforms millions of events into a small number of actionable alerts, no matter where they originate. Watch this video to learn more.

Beyond being the right thing to do, fostering inclusivity in the workplace empowers employees to show up fully as their authentic selves. “BigPanda is the first shop where I have openly identified as non-binary because I felt safe enough to,” said one employee. And considering how much of our life we spend working, BigPanda knows […]

Sony Interactive Entertainment introduced alert quality standards to build high-performing IT systems that reduced manual processes and costs.

A new era for incident management is upon us with the introduction of large language models and IT operations.

Workflow Automation and AIOps streamlines incident management and improves team collaboration. Learn how Abbott’s ITOps team overcame legacy system challenges with BigPanda.

BigPanda brings all your observability, topology, and change data into a single console. Read this best practices guide to learn how to get started.

In light of the macroeconomic environment, BigPanda is announcing that we are streamlining and restructuring to better execute on our mission.

The average cost of an IT outage is $12,900 per minute. Learn which steps IT Operations teams can take to minimize an outage’s impact.

High-quality alerts are fundamental to optimizing an ITOps organization. Learn how alert intelligence can add context and improve the effectiveness of IT alerts.

Every year, BigPanda recognizes employees that demonstrate our core values in their work every day. Read more to see which charities we donated to on their behalf.

Data is power, especially in optimizing IT operations. Creating and reporting the right set of metrics can help IT teams improve efficiency.

Learn how an insurance company reduced IT alerts from 6 million to 50,000 by tracing alerts with BigPanda.

Automating incident management helps more efficiently detect and resolve critical incidents. Learn more about the best practices for IT incident management.

Pragmatic AI has real value for ITOps teams. Learn how AI and ML can assist at any stage of the incident lifecycle.

Digitization of brick-and-mortar stores isn’t new—it’s evolving. Learn how ITOps teams can support this shift.

To celebrate International Women’s Day, female leaders at BigPanda share their experiences as women working in the tech industry.
Dramatically reduce IT noise with innovative alert correlation, powered by AIOps and BigPanda.

Most ITOps teams use a traditional, on-prem tech stack and often two or more cloud infrastructure stacks.

From the rise of AI to global trends in the economy, discover four key ways that tech is set to evolve in 2023.

Confidently building and defending your ITOps budget is crucial to getting the resources you need. Learn three helpful strategies to set yourself up for success.

What will 2023 look like for the industry? Our panel of industry experts share some insights to help you navigate the choppy waters.

Travis Cox, our Regional Vice President of Sales, shares what Black History Month means to him.

BigPanda University was named a finalist for the Awesomeness in Customer Education (ACE) awards presented by CustomerEducation.org.

BigPanda Sales Engineer Kevin Wood shares why he decided to join the BigPanda team.

Explore these use cases for AIOps to see how you can improve productivity, job satisfaction, and service quality from your ITOps teams.

CDI experienced success with BigPanda’s products, first as a partner and now also as a customer.

Exploring the burden of technical debt and what ITOps leaders can do to deal with it once and for all.

In 2022, BigPanda made several product updates to help you quickly adopt AIOps and increase uptime, efficiency, and velocity.

Sanjay Chandra, Vice President of IT at Lucid Motors shares how to scale the NOC globally using AIOps technology, not people.

There’s no cure for IT outages. However, AIOps can help. Valerie O’Connell, Research Director at EMA shares more.

Here’s everything you need to know about CI/CD pipelines but were afraid to ask.

Discover how BigPanda transforms the IT data tsunami into actionable intelligence and automation, enabling incident response teams to increase uptime, efficiency and velocity.

The success of CI/CD depends on collaboration between IT Operations managers, DevOps engineers, and other stakeholders. Learn why CI/CD is important and why.

Discover how to create custom inbound alert integrations through the configuration of a generic, out-of-the-box inbound integration rather than using custom code.

Do you know the difference between CI/CD and ITIL? Read this blog to find out which approach is best for your needs.

Joe Schramm, VP of alliances and channels, comes to BigPanda with the goal of forging mutually beneficial partnerships. Learn more.

Automation, when implemented correctly, can completely transform your ITOps. Here’s what you need to know.
![[Report:] The true costs of modern IT outages](https://www.bigpanda.io/wp-content/uploads/2022/11/blog-real-outage-costs-sm-1080x628.jpg)
BigPanda wanted to uncover the true numbers behind outage costs and it’s more than you think. Here’s what we found.

Whiskey and Wisdom is a monthly executive-only forum where ITOps leaders can network independently and discuss high-level AIOps and ITOps strategies with their industry peers.

Learn more about how simple the Email Parser makes processing important data from your emails.

Working in the NOC can be very scary. Here are some spooky tales from the NOCside.

How much do you know about AIOps and event correlation? In this post we explore everything from its origins to current state-of-the-art techniques and how it fits into integrated service management.

Stakes never have been higher for ITSM in healthcare. Learn more about what’s working and what’s not.

In this blog, we’ll look at event types, use cases for event correlation and approaches that organizations can use to get the most out of this valuable tool.

Erika Streib, new Enterprise Account Executive shares her path as a #WomanInTech and why she chose BigPanda to be her home.

The goal of AIOps in event correlation is to accelerate the identification and resolution of IT issues. Learn more here.

Learn key takeaways from the latest Gartner AIOps Platform Market report to reveal the clearest path to showing value for AIOps.

BigPanda was selected to receive the 2022 Tech Cares Award from TrustRadius. Learn more about how culture drives success.

BigPanda’s enhanced Unified Analytics was designed with our customers’ input. Learn more here.

BigPanda’s Open Integration Manager and Email Parser aim to streamline integrating these kinds of monitoring tools with the BigPanda platform. Learn more.

In our first session from RESOLVE ‘22, we were honored to have Darren Boyd and Satbir Sran from the Incubator podcast and ink8r think tank talk observability and AIOps with BigPanda’s Aaron Johnson. Both panelists are part of communities adopting open standards, and they regularly consult with organizations about how they can improve IT Operations […]

Discover the ease of integrating the ticketing and messaging tools with BigPanda.

Didn’t attend RESOLVE ‘22? Read this blog post for 10 key takeaways for IT Ops leaders.

Tracking IT incident management key performance indicators (KPIs) is a vital step toward minimizing disruptions for customers and users. But metrics alone are not enough to drive improvement in incident management. Learn what KPIs to monitor and how to use them.

Integrating all of your monitoring alert sources is quite a task. Large enterprises often struggle to aggregate millions of data records from dozens of monitoring, change, and topology tools in real-time. Filtering out the noise and prioritizing the most important alerts are crucial to a team’s success. BigPanda makes it simple to integrate with any […]

AI and machine learning are powerful allies in the fight against sprawl and complexity. Three experts weigh in.

Looking for a faster faster path to make more effective use of all the IT resources at your disposal. Start with measuring what matters. Learn more.

What did the pandemic do for innovation? A lot. Read this blog post to find out how AIOps played a role for IT Leaders at Dell and Visionworks.

Do you know which indicators IT Ops leaders can use to measure maturity in DevOps, AIOps and CloudOps? Read this blog to find out.

With a start-up background, Omri was excited about the possibilities that a company like BigPanda could offer, including working with a talented team of people.

For Guy, BigPanda was the perfect organization to bring his global IT as well as military experience and embrace his career aspirations with true flexibility.

AIOps and IT Ops leaders share thoughts on the where they see AIOps going in the next few years.

AIOps is the the future of IT Ops modernization. Read this blog post to find out why AIOps is a strategy, not and not a tool.

During RESOLVE22, Wells Fargo & Honeywell discussed how automation is changing their operating models.

Leaders like Akamai and VMware rely on BigPanda. Read this blog post to find out why.

Four BigPanda customers discuss how they consume and visualize their IT operational data with Unified Analytics.

What do a sinking ship and an improperly equipped data center have in common? Read this blog post to find out.

Multi-cloud is inevitable. With AIOps, struggling in its complexity doesn’t need to be.

When it comes to automating and reducing complexity in the average IT Ops environment, Ryan Taylor says, “look for ways to make your own life (and the working lives of your teams) easier.”

The amount of data volume and complexity within tech stacks is continuing to increase with no sign of slowing down. As a result, many organizations are facing significant challenges related to tool sprawl and the overwhelming amount of data that needs to be exchanged between all the different systems. The result is this new rapid […]

BigPanda is on the cutting edge of AI and IT, but it is also poised to make AIOps accessible to organizations of any size. Read more about our new chapter.

AI and ML are great, but explainable AI and ML are better. Here’s what you need to know.

IT leaders, analysts and thought leaders share what they think the future of AIOps looks like. Here’s what they said.

We talked with Dexcom Director of Cloud Operations, Keith Chernock about how BigPanda’s innovative approach to AIOps has helped usher in a new wave of technological confidence.

Insight Partners is a leader in working with scale-up companies that have existing product/market fit and can use our help establishing best practices for their businesses. But my specific focus is in developer-driven companies. I look for the best technical teams that are building products that developers love and adore. Not only did we find […]

AIOps platforms give technical stakeholders critical data they need to build the high-level views executives typically want before signing off on budgets.

It feels a bit surreal stepping into the Regional Vice President of Sales position here at BigPanda just a few months after the company achieved Unicorn status. In more than 15 years of managing enterprise software sales, this is the first time I knew I was going to play a critical role in facilitating a […]

As an IT leader, Ben Narramore shares what it means to be an incident commander and what he’s learned in the past year.
Whiskey and Wisdom is a monthly executive-only forum where IT Operations leaders can network independently and discuss high-level AI operations and IT Ops strategies with their industry peers. In our most recent session, the discussion was around justifying AIOps—proving the value the technology brings to the table. Demonstrating ROI on AIOps tools requires its champion […]

AIOps will be leading the IT Ops charge. Mohan Kompella, our VP of Product Marketing shares more.

Incident Search and Incident Actions are the newest capabilities for BigPanda self-service APIs. Learn more here.

Looking for a new career? Our VP of Global Sales, Matt Peloso shares why now is the time to join BigPanda.

Chris LaPierre, VP of Customer Success for the West and Central Region shares how our CS team is continuing to serve our customers.

Our Chief Revenue Officer, Rick Underwood shares more on why BigPanda is poised for hypergrowth and his plan to drive towards a successful IPO.

CIO 100 is one of the most prestigious and coveted awards in technology, as it recognizes IT leaders who constantly seek new ways to integrate technology, business processes, and people to drive business agility and innovation for their organizations. BigPanda nominated Sibito Morley because we admire the vision he has, the team he leads and […]

The effects of BigPanda’s most recent round of funding—amounting to $190 million—will be reverberating throughout the company for years to come. And it’s not just BigPanda employees who have experienced a surge of enthusiasm in the wake of our Unicorn status. Our customers are thrilled at the prospect of more innovation from our team and […]

Meet Shikha Gaur, one of our stellar Solutions Engineers at BigPanda.

The BigPanda Value and Adoption team just launched a helpful blog series aimed at bettering your understanding of AIOps maturity. In this first installment, Craig Ferrara, VP of Value and Adoption, shares the importance of self-healing and how Level-0 Automation can transform IT Ops.

At BigPanda, we’re laser-focused on making life easier for IT Ops teams. Here’s how we are helping IT Operations teams keep up.
We’ve recently launched an executive event series, Whiskey and Wisdom, exclusively for IT Ops leaders to gather each month and talk about topics that are top-of-mind (and yes, there is whiskey!).
While the sessions are not recorded, Derrick Arakaki, VP of Customer Outcomes, started a blog called Overheard at Whiskey and Wisdom.
It’s a great way to get a feel for what’s keeping IT leaders up at night, and what ideas they are sharing with their peers.
Every IT Ops team needs to set KPIs, but it can be difficult to know which ones to use, how many to set, and how to derive value from them. In a recent conversation at our Bamboo Lounge community event, we talked with customers about how they tackle setting KPIs.

Each year, we recognize a handful of Pandas that truly went above and beyond to demonstrate BigPanda values in their every day. This year, BigPanda selected 13 recipients to be able to give back to a local organization of their choice. Many of the charities selected are close to these Pandas’ hearts and communities. As […]

At the beginning of the COVID-19 pandemic, we anticipated a slow-down in IT-related spending. In reality, the opposite occurred. Companies massively expanded their digital offerings using the same IT staff they’d had pre-pandemic, even as the teams lost access to many of their existing tools while working from home. This acceleration put immense pressure on […]

I am excited to announce today that BigPanda has secured $190 million in financing at a $1.2 billion valuation. This financing was led by Advent International and Insight Partners, together with our other existing investors. BigPanda is now officially a unicorn, and the clear leader in the rapidly growing AIOps market! Keeping the digital economy […]
Our new ServiceNow integration leverages BigPanda’s latest enhancements to deliver deeper self-service abilities, achieving faster results with no custom integration work.

Learn how Autodesk uses BigPanda’s Event Enrichment Engine to help reduce their IT noise by 95% and substantially enhance their root cause analysis capabilities.

Introducing BigPanda Q4 2021 release: new integrations and self-service APIs that help unify fragmented teams and tools, and accelerate AIOps adoption!

Sharmila S., Senior Manager of the Network Operations Center at LogMeIn In the year since being named an Incident Commander, Sharmila S. — like many — was tasked with helping implement a work-from-home policy during the global pandemic. This, in fact, turned out to be one of her greatest successes over the past year. “It […]

David Levinger, Head of Operations at Machinify Since being named a 2020 Incident Commander, David and his team have worked through a familiar refrain: learning to remain productive in the era of remote workforces. His team has tackled the many challenges that arose in this new paradigm, such as keeping internal and external teams aligned. […]

Success of AIOps tools relies heavily on the quality of data fed to their AI/ML algorithms. BigPanda’s best-in-class Event Enrichment Engine offers cross-domain enrichment capabilities at scale to assure AIOps success.

This year we honored 10 of our top performers by giving back to their communities. We asked each of our Panda Award Winners to choose an organization that we could give a donation to on their behalf. Our top 10 selected 12 amazing organizations. We were able to give $10,000 to our Pandas communities through […]
By Rob Schnepp, general partner at BlackRock 3 Partners, and Jason Walker, field CTO at BigPanda Downtime. It’s more than just a bar on the Rebel Alliance’s base on Folor. For IT Ops teams, downtime is not fun. It costs time, money and often, user frustration. It takes more than the Force to handle incidents…it […]

The future is here. Enter BigPanda and AIOps. BigPanda takes a tools agnostic approach that enables distributed teams to leverage the solution most effective for their needs, while providing IT Ops a centralized and unified manner to standardize incident management processes.

We’re excited to announce the latest enhancement to our Event Correlation and Automation platform that assists responders in triage, one of the most painful parts of the incident management lifecycle. Introducing BigPanda Automatic Incident Triage.

Integration diagnostics and an enhanced ServiceNow integration: doubling down on rapid time to value
Introducing two new major BigPanda releases for even faster time to value: Integrations diagnostics, and an enhanced ServiceNow integration.

Introducing BigPandaU and its first offering: the Getting Started video series, where you can learn how to easily set up and start using BigPanda.

The 2 most important Gartner strategic 2021 tech trends for IT Ops, and how BigPanda can help realize them.

Insights from our “IT Ops Ready” virtual summit, featuring sessions from NTT Data, AWS, Fanatics, Wiley, Ulta Beauty, Gentworth and many more!

Learn how Expedia modernized operations on their complex and fastest-moving IT stacks, and why they chose the BigPanda AIOps platform to help them with their mission.

Leading analysts continue to acknowledge BigPanda’s leading role in the AIOps ecosystem – this time in EMA’s Radar Report on AIOps.

“Under-the-hood” visibility into the mechanics of IT Ops tools can provide teams with advanced self-service configuration, debugging and troubleshooting capabilities.

B2B self-service is here. What do we need to do to create a self-service driven AIOps solution?

Watch and read about our “IT Ops from Home” virtual summit with sessions featuring Sony Playstation, State Farm Insurance, Ulta Beauty, AWS and BlackRock 3.

Monitoring modernization can be a daunting task. But following a few tried-and-tested methodologies can help ease the pain.

Tribal knowledge in IT Ops doesn’t have to be a challenge. If handled properly – it can actually become an asset.

Learn how BigPanda’s Root Cause Analysis features allow you to embrace the chaos of modern, fast-moving IT environments.

Headed to Gartner IOCS in Las Vegas? We are too. Here’s where you can find us during the conference.

With over 80% of outages caused by changes, Root Cause Changes is a key element in IT incident resolution. See how our Beta customers used our newest capability.
Until now, IT Ops, NOC & DevOps teams didn’t have an easy way to understand “What Changed?” when dealing with outages. Meet BigPanda’s Root Cause Changes.

Many IT leaders are considering AIOps solutions in their quest to keep systems running 24x7x365. What should they be looking for?

The results of our AIOps survey are in. Here’s what 1300 IT Ops professionals say about the future of automation, AI & ML and their role in the enterprise.

This playbook from CIO Dive explains how AIOps tools can reduce IT noise, detect problems, surface probable root cause, reduce ticket volumes & slash MTTR.

Kelly Looney, Global DevOps Lead at AWS, discusses the challenges IT Ops teams face as they embrace the cloud & why AIOps tools like BigPanda can be a solution.

ITOps teams are challenged today like never before, overwhelmed by IT noise and constantly fighting fires. Is AIOps the solution for noise reduction?

When implementing AIOps you can choose between a revolution or an evolution path. How do you know what’s best for your business?

Being an intern at BigPanda can be one of the most rewarding experiences you can imagine. Anthony Caldiero, who joined our Sales team for the summer, shares his experience.

Have an immature CMDB, or no CMDB at all? No problem, BigPanda can still correlate your alerts and drastically reduce your IT noise.

BigPanda is proud to be driving the adoption of AIOps in leading enterprises as an inaugural member of the new AppDynamics Integration.
In this new whitepaper, noted industry analyst Nancy Gohring of 451 Research delivers an in-depth look into the future of AI & ML-enabled IT Ops.

Do you make the most of the data generated by APM/NPM tools? Learn how AIOps can help your NOC and IT Ops teams finally take full advantage of the deep insights hiding in this data.

BigPanda shines at the Trace3 Evolve Leadership and Technology Conference.

Hundreds of tickets, critical information missing, duplicate and wasted efforts, and more. Can AIOps Tools solve your Service Desk problems?

It’s not just our customers who choose our technology time and again. BigPanda is also recognized by the industry as an award winning innovator.
Overwhelmed with data and noise, enterprises (and cockpits) need AI and ML enabled s solutions to run faster, more efficiently and at a lower cost.

Overwhelming IT noise is enterprises #1 enemy. Can IT Ops tools powered by AI/ML (aka AIOps), like BigPanda, help them?

As applications and infrastructures become more complex, it’s time to say goodbye to monolithic solutions and build a best in breed stack, with BigPanda.
Katie Volz, Regional Sales Director strongly believes company values do matter, if we put enough thought into defining them, and then make sure we live by them. They can actually make all the difference.

You’ve just recovered from a critical application outage and your team is being asked to report on root cause and recommended remediation steps later this afternoon. Can you quickly analyze all the data, identify all the leading events, and discern which one was responsible for the cascading failure? Later that week, you are back to […]

BigPanda will enable your engineers to be actual engineers and your NOC teams to fully support your new projects, services and applications.

Machine Learning innovator BigPanda has found the recipe for a successful offsite meeting. Want to know what it is? Read this post.
IT operations teams have some of the most stressful jobs in IT. Keeping data centers online, servers running, enterprise systems functioning, and applications performing — all while responding to incidents and requests is hard work. While there are monitoring systems in place to provide visibility and change management practices that give IT some control over the […]

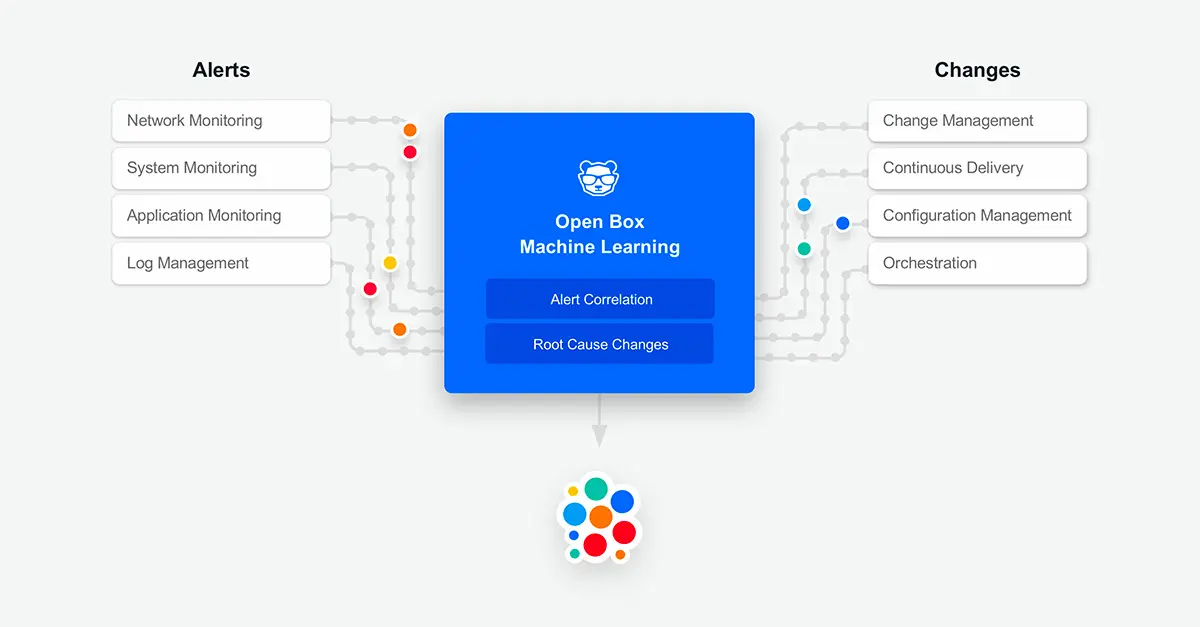
This is the first in a series of blog posts on Open Box Machine Learning. If you’re part of a large enterprise, you’re probably in the throes of digital transformation. If you’re in IT, you’re supporting your business by rolling out new services and apps weekly (or even daily). Meanwhile, your users expect 24×7 availability […]

It was a big week for BigPanda at the Gartner IT Operations Strategies & Solutions (IOSS) Summit, which was held May 15-17th in Orlando, Fla. More than the Big News we announced and our CEO Assaf’s presentation, we enjoyed more than 700 high-quality interactions at Gartner IOSS Summit with senior enterprise IT leaders. Gartner’s theme this […]

Orlando, here we come! BigPanda is excited to be a Platinum Sponsor of the upcoming Gartner IT Operations and Strategy Summit, kicking off in sunny Florida on Tuesday, May 15th. We’re even more thrilled that our CEO Assaf Resnick has been chosen to be among the prestigious list of Gartner IOSS Speakers. Gartner’s theme this […]

We’re happy to have Rise Broadband as one of our customers. We’re especially thankful for their willingness to share their story of how they overcame NOC challenges to improve service availability, gain better visibility over operations, and boost the productivity of their NOC team. If you’re not familiar, Rise is the largest fixed wireless service […]

Any organization can be defined by its operating principles. These are the fundamental norms, rules and values that represent what is desirable and positive for the group. Having well defined principles can help an organization operate as a “community” with a shared understanding of what is right and what is wrong. It’s key that these […]
For the past year or so, productivity experts have been talking about “Inbox Zero” – a rigorous fresh approach to email management. Reaching Inbox Zero stresses techniques to tame your inbox and keep it empty (or nearly empty) at all times. The practice promises to focus your time and attention on the most important tasks. At an […]

BigPanda exhibited and moderated a customer success panel at Gartner’s big IT Infrastructure, Operations Management & Data Center show in Las Vegas last month. The Gartner I&O Conference is action-packed, so it’s taken me awhile to digest all the great information and insights I gathered there. Gartner’s influence in the enterprise IT operations market is undisputed. […]

One of the world’s largest television and digital entertainment companies had a problem. A company-wide initiative to reinvent its service delivery demanded that IT help make its content available anytime, on any device. As a global media conglomerate, its enterprise spans numerous entertainment, news and sports networks – including broadcasts of major league basketball. Customer […]

Part 1 of this series defines algorithmic alert correlation and how it works. The term “algorithmic” describes how data science applies machine learning techniques to solve alert storms, aka alert floods. There are two flavors of machine learning currently being applied to this problem: one is “black box” and the other, “open box”. BigPanda applies open […]

The IT Operations tool stack is becoming exponentially more complex. This requires the utilization of a breadth of diverse monitoring tools in order to quickly detect and ultimately resolve critical issues before they can inflict real damage on the business. Most large enterprises already have a host of preferred monitoring tools installed and working. It […]

In his research note “Four Steps to Turbocharge Your Major Incident-Handling Capabilities”, Gartner analyst Kenneth Gonzalez makes a compelling argument for why enterprise IT service operations teams should upgrade their incident management workflow processes. Here’s BigPanda’s perspective on the topic. The Real Challenge: Most NOCs Aren’t Automated Most enterprises are undergoing some form of digital […]

What a week! Our team spent 5 days in Orlando last week, representing BigPanda at both Gartner’s IT Operations Strategies and Solutions Summit and ServiceNow’s Knowledge17 conferences. Here’s our wrap up on Gartner IOSS. Hundreds of enterprise IT leaders gathered in at the Hilton Orlando this past week to learn how IT can take advantage […]

Is your team ready for 2017? Featuring early release findings from BigPanda’s forthcoming State of Monitoring Report, our latest e-book takes a look at how key industry trends will affect IT operations in the upcoming year.

Life just got a whole lot simpler. BigPanda is pleased to announce the launch of our upgraded BigPanda FAQs. The new location, look, and feel of the site make it easier than ever to access the information you need to be successful with BigPanda. Here are a few benefits of the upgrade:

Decompressing from an exhausting, inspirational few days at Knowledge16, the annual ServiceNow event…
From humble beginnings (my first Knowledge was a few hundred attendees in a tent in San Diego), Knowledge has become a global tour de force. This year, Mandalay Bay could barely contain more than 11,000 customers and partners (and the expo hall could barely contain more than 100 decibels of the tech equivalent of Queensryche). Getting into the keynote felt like rush hour on the subway in midtown Manhattan.

Ask yourself these questions to find the right fit in an alert correlation platform.
To maintain operational visibility in modern IT environments, companies are abandoning monolithic monitoring solutions from legacy vendors in favor of a modern set of “best of breed” monitoring tools. Today’s average IT monitoring stack consists of about 6-8 tools, including at least one from each of the following categories: systems monitoring, end user monitoring, application performance monitoring (APM), error detection, log analytics, chat, and ticketing. When service disruptions occur, operations engineers face a flood of alerts across different layers of the IT stack, with no fast way to figure out what’s really going on. Customers are left stranded, while IT professionals struggle to detect, triage and remediate urgent issues. Downtime abounds which negatively impacts revenue, performance, and brand loyalty.

For a bunch of data nerds, we’re glad to say that we can officially sit at the cool kids’ table. We’re proud to share that Gartner, the world’s premier information technology research and advisory company, has selected BigPanda as a “Cool Vendor” in Availability and Performance.
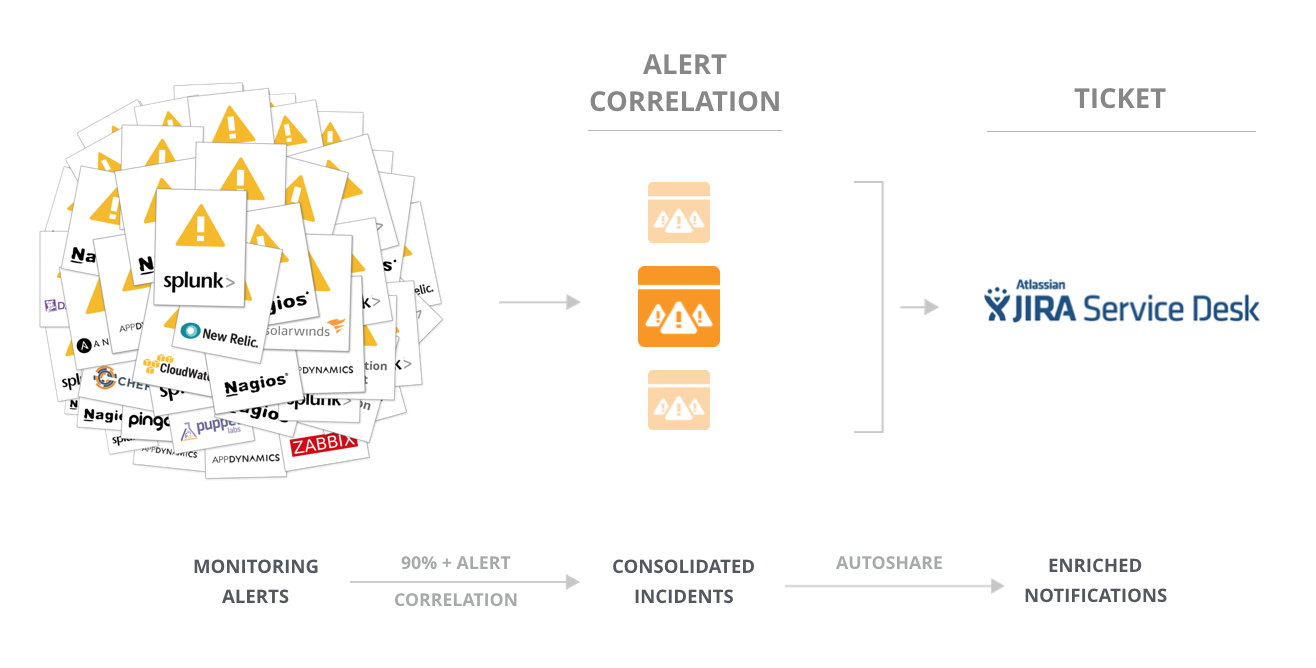
This post was recently published as a guest blog by our friends at Jira Service Desk. You can find the original post here.
We all need to move fast in order to stay competitive. But the faster things move, the faster things break.
While many companies have made great strides towards automating application release and infrastructure management, automation for service assurance has been sorely lacking. That’s left Dev and Ops with a problem: how to effectively service alerts that have grown by orders of magnitude.

You and Nagios have had your share of ups and downs, but lately it just hasn’t been the same. You’re busy with other systems and having less patience to deal with the constant nagging from good ol’ Nagios. She’s beginning to sound more and more like a broken record.
If you keep going down this path, your MTTR will suffer. Or worse, you won’t be able to satisfy your customers. But you’re not ready to give up on Nagios just yet – after all, she’s been there when you needed her.


For many IT and Ops teams, Nagios is both a blessing and a curse. On the one hand, Nagios gives you near real-time visibility into the inner workings of your IT infrastructure. But on the other hand, Nagios can generate so many alerts that it’s impossible for any single person (or even any team) to keep up.
This is part two of a two-part post about using event correlation to thwart DDoS attacks. Channeling Mark Twain: it would have been shorter if I had more time. In the last post I described why DDoS attacks for SaaS providers are no different than performance and availability issues experienced in other domains like healthcare, finance, or retail. In this post I’ll share a customer story about a security breach that never happened… thanks to a savvy DevOps team and data science.

Every company’s a target, every customer’s at risk. But the now-cliched threat of data breaches from Distributed Denial of Service (DDoS) attacks obscures a bigger threat: outages that impact not just data integrity but also profitability, brand equity, and customer retention.
The volume of attacks is growing and so is the impact of down time. According to Akamai’s most recent State of the Internet report, DDoS attacks are a bigger threat than ever before. “The number of DDoS attacks continued to increase substantially in Q2 2015, more than doubling the number observed in Q2 2014.”
At BigPanda, we’re committed to giving you the tools and information you need to be successful. In keeping with this goal, we’re excited to announce BigPanda Docs, our revamped help documentation that features more content, better navigation, and more ways for you to give us feedback.

Today, I’m happy to announce that BigPanda has raised $16 million in Series B funding. Battery Ventures led the round, with participation from existing investors Sequoia Capital and Mayfield. We are thrilled to call them all partners.

Enterprise application and computing environments have changed radically over the past fifteen years. Anyone who has spent even a day in an IT role can tell you that.What gets less attention, however, is how those changes undermine the ability of operations teams to do their jobs. The problem is that as computing and application environments have changed dramatically, workflows and org charts have not.

Data center growth over the last 15 years has created significant growing pains in terms of data center management. Tasks that once could be done manually by IT teams have hit the limits of scalability, cost, and efficiency. The key to enabling IT to meet these challenges involves one key theme: automation.

Ansible is a great automation tool. We use it for server provisioning, application deployments and running maintenance scripts. One problem it does have however, is how (in)convenient it is to run playbooks as opposed to regular shell scripts. Write and run enough Ansible playbooks, and eventually you’ll get tired of the repetitive typing your fingers have to do.

Modeling your production environment correctly is very important for development. Developers need to be able to run and test their code locally for the development process to be efficient, and many times this requires setting up infrastructure that exists in production on their local machines. The basic solution is a simple Vagrant box containing all your infrastructure and application code, like the one we mentioned in our Devbox post.
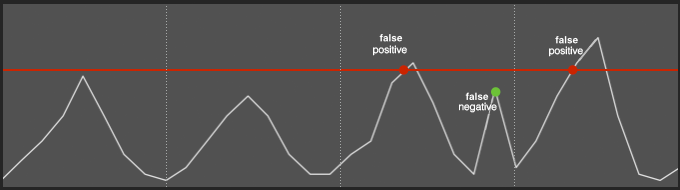
Anomaly detection for monitoring has been a trending topic in recent years. And while the math behind it is fascinating, too much of the discussion has revolved around histograms, moving averages and standard deviations. More discussion needs to happen around its practical applications, and for that reason, this practical guide to anomaly detection will attempt to provide an actionable overview of current off-the-shelf anomaly detection tools.