What is mean time between failures? Why does it matter?


Mean time between failures (MTBF) measures the average duration between repairable failures of a system or product. MTBF helps us anticipate how likely a system, application or service will fail within a specific period or how often a particular type of failure may occur. In short, MTBF is a vital incident metric that indicates product or service availability (i.e. uptime) and reliability.
A higher MTBF signifies a more dependable system, so organizations strive to maximize this duration and put hundreds of thousands of hours between issues. When paired with AIOps, and its features around event correlation, automated root cause analysis, and automated incident response workflows, you can avoid costly breakdowns, maintain your Service Level Agreements (SLAs), and keep that hard-earned customer trust.
How do you calculate mean time between failures?
Calculating MTBF is simple: divide the total operating hours by the number of failures in that period.
- Step 1: Calculate the number of operational hours of your product or service.
# of hours of uptime – # of hours of downtime = # of operational hours - Step 2: Once you have the number of operational hours, calculate your MTBF.
# of operational hours ÷ # of failures = MTBF
Let’s calculate MTBF using an example. Say that your system was available for 1000 hours in a year and experienced two incidents, each resulting in an hour of downtime for two hours of downtime total.
- Step 1: 1000 hours of uptime – 2 hours of downtime = 998 operational hours
- Step 2: 998 operational hours ÷ 2 failures = 499 hours of Mean Time Between Failures
What is a good mean time between failures?
A system’s MTBF depends on many factors, from how your system is set up to when the initial alert is received to ticket creation to remediation. There isn’t a universal “good” MTBF for every use case. Instead, determine a reasonable MTBF for your system based on historical data and similar systems. The more data you collect, the more accurate your MTBF will be.
Why calculate the mean time between failures?
MTBF is used to anticipate how likely an asset will fail within a specific period or how often a particular failure may occur. When paired with other maintenance strategies like failure codes, root cause analysis, and other measurements, MTBF helps us avoid costly breakdowns.
Calculating MTBF makes it easier to create preventive maintenance strategies, so reliability can be improved by tackling issues before they cause failure. However, MTBF does not consider the failures’ severity or its impact on operations or systems, which is why it’s also essential to understand your MTTR.
MTBF vs. MTTR: What’s the difference?
MTBF and MTTR are two important reliability measures, but they differ in what they measure.
- MTBF tells us how long a system typically works without breaking unexpectedly. It’s calculated by dividing the total operating hours by the number of failures in that period.
- MTTR typically refers to mean time to resolve, but it can also represent mean time to repair or mean time to respond. In our case, we use it to refer to mean time to resolve, which is the average duration needed to completely fix a problem and get back to service. This includes the time spent identifying the issue, analyzing the problem, and performing the necessary repairs.
This metric extends the responsibility of the team from simply fixing the problem to improving its performance long-term. It’s the difference between putting out fires versus fireproofing your house. Given the strong correlation between MTTR and customer satisfaction, keeping MTTR low is critical to keeping customers happy.
MTBF indicates system reliability and availability
MTBF helps us understand how well our maintenance works. It’s linked to reliability and availability. The higher the MTBF, the more reliable and available the system is.
- Reliability and MTBF: Reliability means how likely a system or part is to work without problems over a specific period. MTBF is a simple way to measure reliability — the higher the MTBF, the more reliable the product. By using MTBF along with other measures of failure and maintenance plans, teams can better predict when something might break and take steps to prevent it.
- Availability, MTBF, and MTTR: Availability is how well a system or part can work when needed. Combining MTBF with mean time to resolve (MTTR) helps determine the chance of a system failing in a certain period. You can find a system’s availability by dividing MTBF by the total sum of MTTR and MTBF. This helps us understand how often a system is unavailable for use.
Improve your MTBF
Once you have a baseline MTBF, you can improve it through the following methodologies: optimizing data collection process, reducing event noise, making alerts actionable, automating root cause analysis, and using analytics to understand better where and how to improve incident workflows.
- Alert Intelligence: Transforms millions of events into a small number of actionable alerts to greatly reduce your risk of missing critical alerts. Reduce IT event noise and add context to the remaining events to transform incidents into actionable alerts.
- Incident Intelligence: Leverage AI/ML-driven alert correlation engine to detect and triage incidents. Give first responders the insights they need to rapidly resolve more incidents independently without escalating to L2/L3 resources.
- Automating root cause analysis: Allocate more time to investigate the root cause of system and product failures. This ensures you address the underlying causes for lasting solutions, rather than quick fixes to resolve recurrent issues effectively.
- Generative AI for Automated Incident Intelligence: Automate incident analysis to speed resolution and reduce escalations.
- Unified Analytics: Explore interrelated ITOps KPIs, monitor your MTBF report (shown below), and get insights into increasing productivity and standardizing incident response workflows, to boost uptime for critical applications and services.
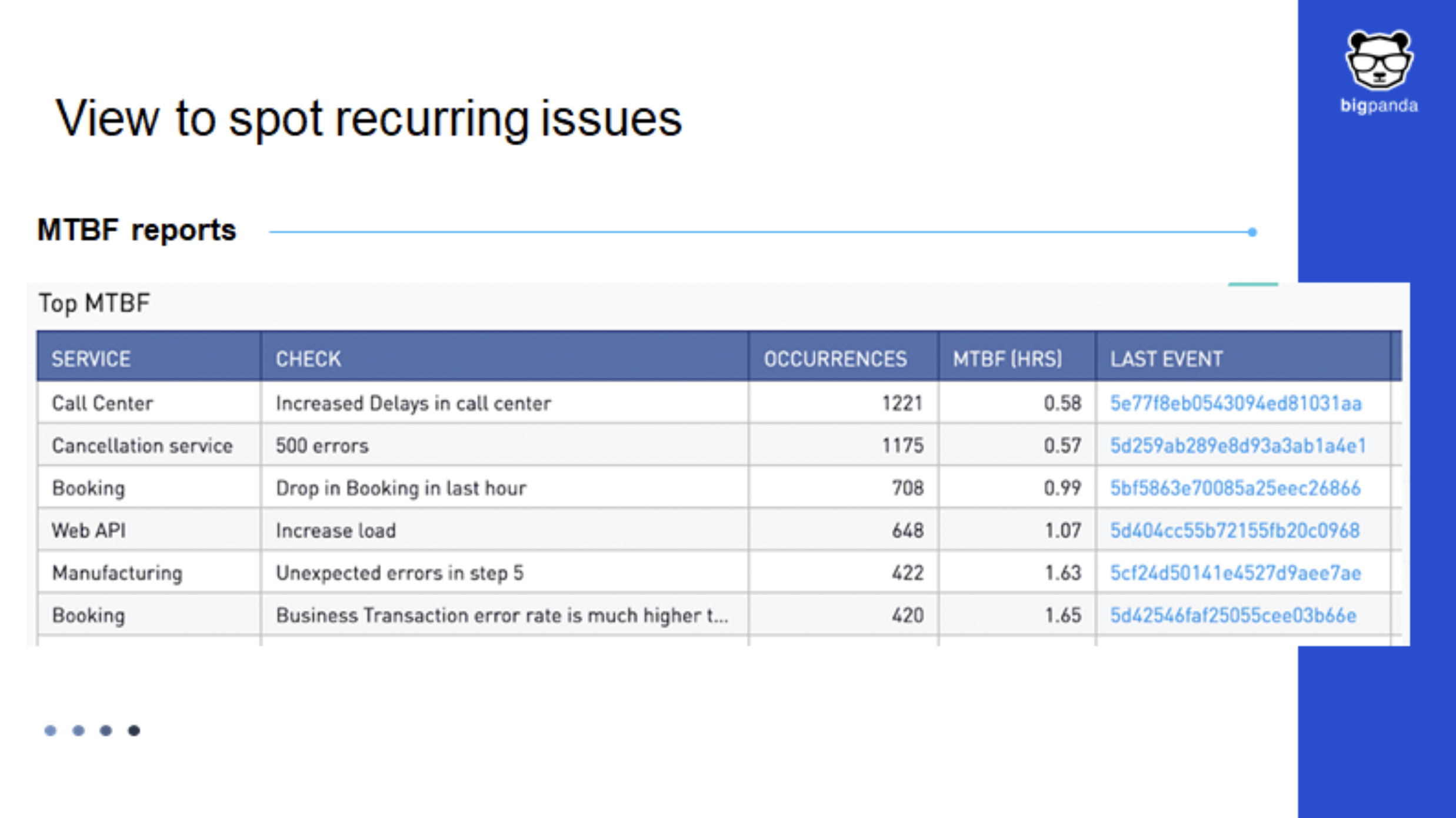
Increase MTBF to improve availability and customer satisfaction
Reliability metrics like MTBF and MTTR are crucial to keeping your systems running and availability goals met. These and other related incident metrics are critical in assessing and improving system reliability and performance. That’s why tracking these metrics is essential to making informed decisions to minimize downtime and enhance operational efficiency.
You can track MTBF and MTTR with Unified Analytics from BigPanda, the only purpose-built analytics and reporting solution for ITOps. Unified Analytics provides extensive visibility into KPIs, reliability metrics like MTBF and MTTR, and trends to optimize continuous incident workflow. Demo the BigPanda platform to see Unified Analytics in action and explore interrelated ITOps KPIs to gain insights into increasing productivity, standardizing incident response workflows, increasing uptime, and ultimately, keeping customers happy.