



The BigPanda agentic IT operations platform
Built for enterprise IT operations teams, one AI-powered platform for preventing, detecting, triaging, and resolving incidents

Enterprises spend $250 billion annually on manual, human-driven IT operations, and it doesn’t scale
The BigPanda agentic ITOps platform represents the evolution of AIOps, delivering agentic AI automation for ITOps and ITSM teams. Watch the video to see how BigPanda automates complex manual workflows and empowers enterprise IT teams to reduce operational costs and stop IT incidents before they happen.
What is BigPanda?
BigPanda keeps the digital world running by transforming reactive, manual IT processes into proactive, intelligent automation. The BigPanda agentic IT operations platform uses AI to prevent, detect, and respond to IT incidents, improving operational efficiency and delivering exceptional service reliability. From L1 automation to major incident management and proactive change governance, BigPanda re-imagines AIOps for the future of ITOps.
AI Incident Prevention
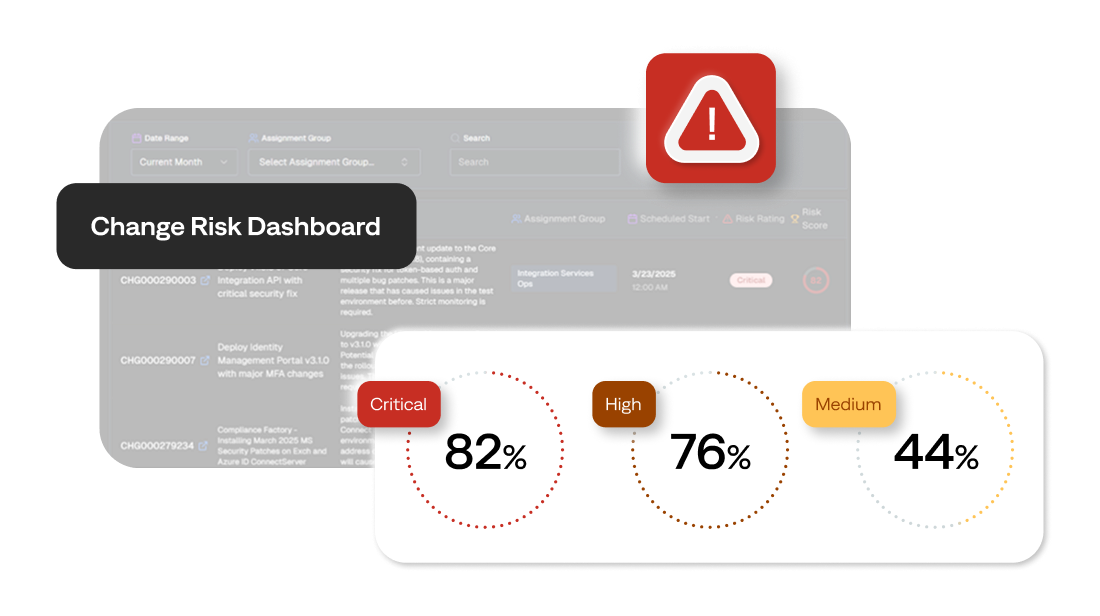
Automated change analysis enables proactive and scalable change governance, preventing future incidents and improving service reliability.
-
- Change risk management: Detect and assess high-risk changes with AI-powered change risk intelligence. Provide your teams with clear risk scores and actionable mitigation recommendations to prevent rollbacks and preserve high-value engineering time.
- Problem management: Uncover recurring patterns, surface fixes, and guide teams to resolve underlying issues with AI-powered root cause analysis. Prioritize remediations by effort and impact to resolve problems at scale.
- Governance: Establish guardrails that empower business teams to operate with confidence, autonomy, and speed.
AI Detection and Response
Correlate signals and surface critical context so your teams can detect and diagnose incidents faster, before they escalate.
-
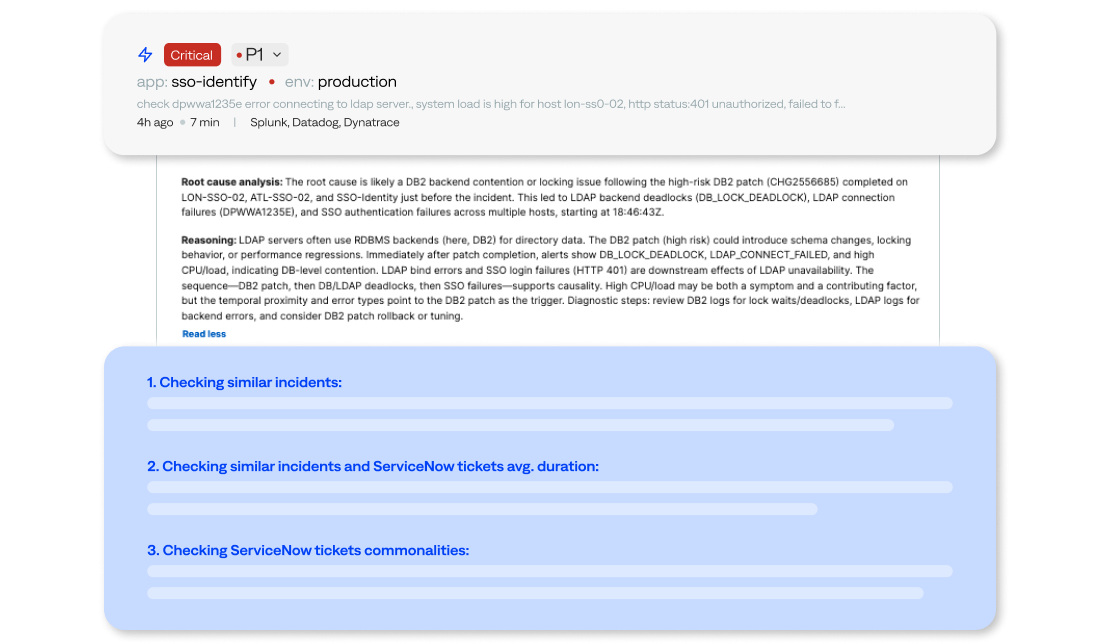
- Detection: Identify incidents before they impact services using AI-driven correlation across observability, service desk activity, and external service provider dependencies. Cut noise and spot systemic issues early.
- Triage: AI agents gather insights from service desk activity, past incidents, change data, and external observability sources. Every incident arrives with a unified summary and suggested next steps, with no manual investigation required.
- Response: Surface runbooks, historical resolutions, and root cause context so the right team can act immediately. Escalate only when necessary, with context-rich tickets that eliminate rework.
L1 Agent
Scale L1 operations without scaling headcount. An AI-native operator handles repetitive, high-volume work, so your team can focus on tasks that require human judgment.
-
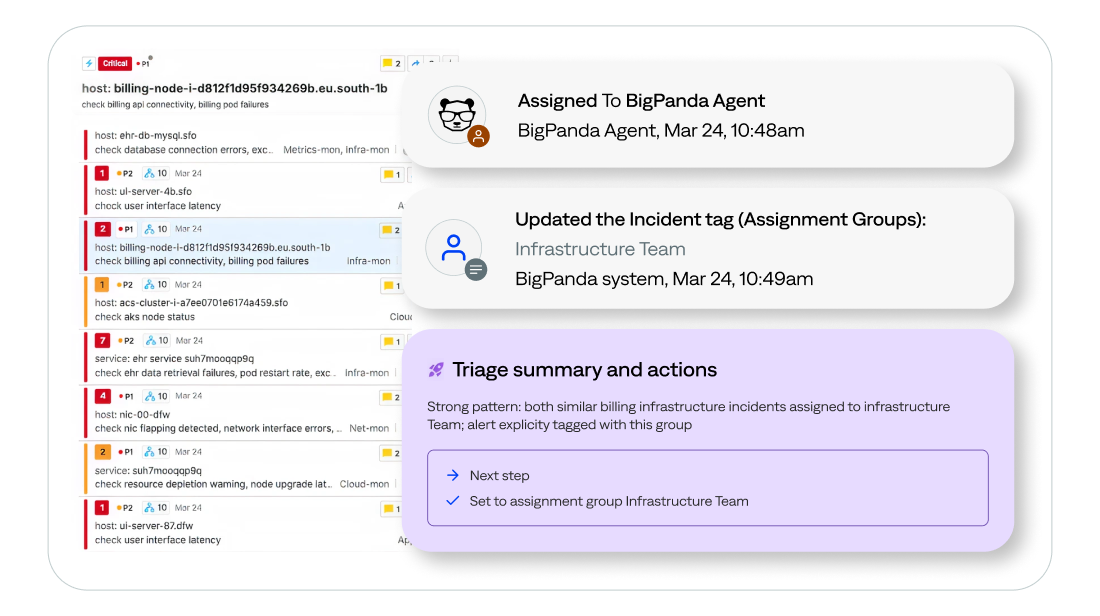
- Automated assignment and suppression: Every incident is automatically routed to the right team. False positives, noise, and auto-resolved alerts never reach the queue. Agents handle them before operators ever see them.
- Resolve more at L1: L1 Agent applies AI reasoning across real-time incident data, historical outcomes, and operational knowledge to resolve incidents autonomously. It escalates only when genuinely needed, and always with the full context attached.
- An intelligence layer that compounds over time: Built on the BigPanda IT Knowledge Graph, L1 Agent learns from your environment continuously. Routing accuracy improves, noise gets filtered faster, and the system gets smarter with every incident. No rules required.

AI Incident Assistant
Give incident escalation teams an always-on AI partner to improve collaboration, accelerate investigation, and automate resolution.
-
- Investigation: Troubleshoot incidents dynamically in natural language to quickly reveal what’s happening, why, and how to fix it. Use AI agents to shorten the time spent accessing multiple tools and searching scattered documents.
- Collaboration: Replace manual incident coordination with autonomous agents that spin up incident channels, loop in the right SMEs, and summarize key findings in real time.
- Automation: Build AI-powered workflows for common tasks in minutes, no code needed. Simply describe the automation using a drag-and-drop interface.
AI-powered data foundation
The BigPanda IT Knowledge Graph unifies your observability, ITSM, and organizational data to deliver out-of-the-box insights, clear risk scores, and accurate root cause analysis, eliminating the need for manual reviews and siloed data collections.

Trusted by global enterprises
![]()
Real-time triage
“[The AIOps platform] saves us time, letting us focus on resolving problems instead of combing through thousands of alerts to find the problem. It’s transformational and game‑changing”
![]()
Faster incident detection
“Centralizing our operations with AIOps and BigPanda allowed us to have a much faster MTTD, which gave us a head start in resolving operational incidents. BigPanda keeps our costs down.”
![]()
Fewer escalations and tickets
“Don’t wait to start your AIOps journey once you are overwhelmed with alerts. Start early to get a single pane of glass to understand which monitoring tools you really need.”
FAQ
What is agentic IT operations?
Agentic AI for IT operations goes beyond AIOps and integrates autonomous AI agents into IT operations to detect, diagnose, respond to, and prevent infrastructure issues with little to no human input.
How does BigPanda provide additional context for enterprise ITOps?
BigPanda enhances incident context by ingesting and normalizing data from diverse sources, including topology, configuration management database (CMDB), and change data. BigPanda multidimensional alert correlation and AI Incident Assistant offer deeper insights and automate root cause analysis (RCA) for quick, informed decision-making. This comprehensive approach goes beyond other AIOps solutions, enabling teams to resolve incidents efficiently using a holistic view of system interconnectivity and operational impacts.
Does BigPanda work across hybrid systems?
Yes. The BigPanda agentic ITOps platform supports both on-premises and cloud-based workloads and integrates with popular monitoring and observability tools. The BigPanda open integration manager also facilitates custom integrations. By unifying on-premises and cloud topologies, you gain comprehensive visibility across environments and identify opportunities to enhance digital transformation efforts.
What is L1 Agent, and how does it fit into the BigPanda platform?
L1 Agent is an AI-native operator purpose-built for L1 workflows. It automatically analyzes and assigns incidents using AI reasoning, drawing on real-time data and operational knowledge. Within the BigPanda platform, L1 Agent sits alongside AI Detection and Response, which provides the event intelligence and agentic triage context that L1 Agent draws on to act accurately. At the same time, the L1 Agent handles high-volume, repetitive work.
How do BigPanda products work together?
The BigPanda platform covers the full incident lifecycle. AI Incident Prevention stops incidents before they start through change risk analysis and problem management. AI Detection and Response surfaces early signals and correlates context across your environment. L1 Agent uses that context to analyze and assign incidents at the L1 level automatically. AI Incident Assistant supports L2, L3, SRE, and major incident teams with investigation, collaboration, and post-incident reporting. The IT Knowledge Graph powers all four, creating an intelligence layer that compounds over time.
Check out more related content


DEMO
See the BigPanda agentic ITOps platform in action.


- PlatformPlatform
- Agentic IT Operations
- Platform Overview
- AI Incident Prevention
- AI Detection & Response
- L1 Agent
- AI Incident Assistant
- IT Knowledge Graph
- BigPanda AIOps
- BigPanda Core
- Advanced Insight
- Biggy AI
- Rebranding Matrix
- Integrations
- Security & Compliance
- Features
- Detection
- Open Integration Hub
- AI Detection
- Diagnosis
- Service Desk Correlation
- Suggested Actions
- Incident Correlation
- Triage
- Automated Incident Triage
- Root Cause Analysis
- Similar Incidents
- Prevention
- Change Risk Management
- Problem Management
- Solutions
- Automating L1 Detection & Response
- Empowering Experts with AI Assistance
- Predicting & Preventing Disruptions
- Personas
- IT operations
- Incident management
- IT service management
- Site Reliability Engineering
- Industries
- Financial services
- Manufacturing
- Insurance
- Media and entertainment
- Managed services
- Airlines
- All industries
