



Root Cause Changes – IT Ops, NOC and DevOps Teams’ Best friend For Supporting Fast-Moving IT Stacks


TL;DR: Fast-moving IT stacks see frequent, long and painful outages. Thousands of changes – planned, unplanned and shadow changes – are one of the main reasons behind this.
Until now, IT Ops, NOC & DevOps teams didn’t have an easy way to get a real-time answer to the “What Changed?” question – the answer that can help reduce the duration of outages and incidents in these fast-moving IT stacks.
Now, with BigPanda Root Cause Changes, they do.
***
But every product and every feature has a story – the why, the what and the how.
Here’s ours.
***
Unsung Heroes
Having trained and worked alongside NOC techs and L2s and L3s for many years, I can say without exaggeration that these teams are some of the hardest working teams inside IT.
On top of that, because there’s always a fire to put out, or two, or three, these teams are also constantly stressed-out. And dealing with irate customers every hour, every day – both internal ones, and external ones – just goes with the territory.
But on those days – few and far in between, unfortunately – when things are going well, and there are no outages or incidents, it’s like these teams are invisible.
That’s why I think they are the unsung heroes in IT orgs everywhere.
Modernizing Enterprises and Fast-Moving IT Stacks
As enterprises of all sizes have started to modernize – and move to the cloud, and build cloud-native apps and architectures – their IT stacks have started to move faster.
By that, I mean that these modern IT stacks change all the time (thousands of changes every day, every week) and the topologies of their applications are constantly in flux (changing by the minute, if not more frequently).
Tasked with supporting these fast-moving IT stacks and modern applications and services – our unsung heroes, IT Ops, NOC and DevOps teams in IT orgs everywhere – must contend with more frequent, longer, and more painful outages and incidents.
Still reliant on legacy IT Ops tools built for slow-moving IT stacks, these teams are stuck between the proverbial rock and the hard place.
But Why are Outages and Incidents Longer?
Well, if you split an incident into its constituent parts, you get three things: detection, investigation and remediation.
Detection or triage is measured by metrics such as MTTD (mean-time-to-detect) and the use of AI/ML have largely solved this problem today.
Remediation – aka the time it takes to implement the fix, once the source of the problem is identified – is also relatively straightforward. In many cases, this is also the step that takes the least amount of time.
Investigation – getting to the source of the problem via Root Cause Analysis (RCA) – is where it breaks down, especially in fast-moving IT stacks.
Why?
Let’s continue.
The Good Old Days of CMDBs
To be clear, root cause analysis was never easy. But it was, in many ways, simpler in the past.
A bad storage array, a log file that was full and preventing an app from writing to it, a port on a switch that was unresponsive and making all downstream servers unresponsive and so on and so forth.
And that’s when CMDBs populated by discovery agents that ran once a week provided enough context and topology to get to the root cause of outages and incidents and fix them.
Where there was an outage, an incident or a disruption, NOCs opened a ticket. The service desk looked at the CI and looked at what changed for the CI in the last day or two. They identified the change, rolled it back and everyone was happy.
Or maybe their ITSM tool automatically surfaced the change associated with the CI experiencing a problem, the NOC kicked off a shell script or an orchestration tool to roll back the change and everyone was happy.
Or some combination of those steps – with the common thread being a reliance on a mostly accurate and up-to-date CMDB.
CMDBs vs Fast-Moving IT Stacks
Fast forward to 2019 or 2020, and hardware has largely been abstracted away in fast-moving, cloud-native architectures and applications.
IT orgs just take it for granted that their cloud-native apps and services are not going to fail because of full disks or bad network ports any more.
But there is something new that IT operations teams have to contend with in the cloud. Two new things actually: thousands of changes every day or every week, and application and service topologies that shift by the minute.
Where are these changes coming from? Your CI/CD pipelines, orchestration tools, change audit and log tools, and others.
What’s causing dynamic topologies? Container management tools, Kubernetes, and more, that keep your cloud-native architectures elastic and resilient.
What does that do for your CMDB-driven RCA strategy?
It renders it largely useless.
There’s just no way that legacy CMDB systems – designed for slow-moving IT stacks – can track thousands of changes and ever-shifting application topologies.
That’s why legacy RCA techniques break in fast-moving IT stacks, causing long and painful outages and incidents.
So Here’s What BigPanda Launched
To help IT Ops, NOC and DevOps/SRE teams fast-track incident resolution in fast-moving IT stacks, BigPanda launched two brand-new AIOps capabilities this week:
1) Root Cause Changes
The idea is simple.
Because 60 – 90% of all outages and incidents are caused by changes today (a statistic gathered from our customers and prospects), we asked ourselves why we couldn’t
(a) gather changes from all the change feeds and tools used by enterprises
(b) put them next to all the alerts gathered from all the monitoring tools used by enterprises (an existing BigPanda capability)
and then,
(c) use Machine Learning to analyze and match both datasets together to identify the root cause change behind an outage or incident?
That’s exactly what our R&D and Product teams did.
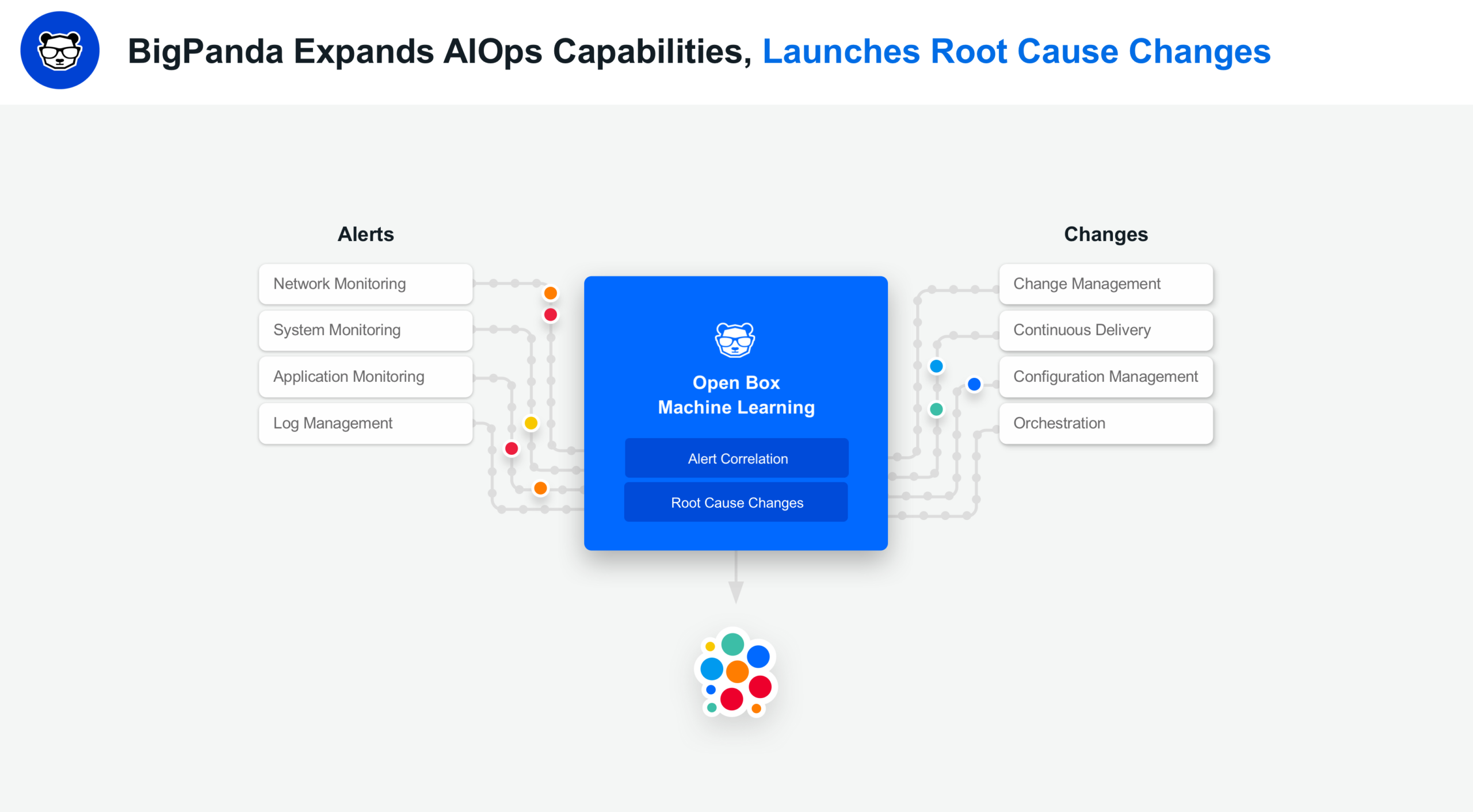
They worked on our new Root Cause Changes feature for the last several months (simple ideas and simple user experiences require tons of behind-the-scenes work…this is exactly what Apple does too, we think we’re in great company there!), then invited a select group of large customers with complex fast-moving IT environments to beta test it, and launched this feature publicly this week.
2) Real-time Topology Mesh
The idea here is simple too.
Modern topologies are incredibly complex, multi-layered beasts, and different components of modern application and service topologies live in different tools.
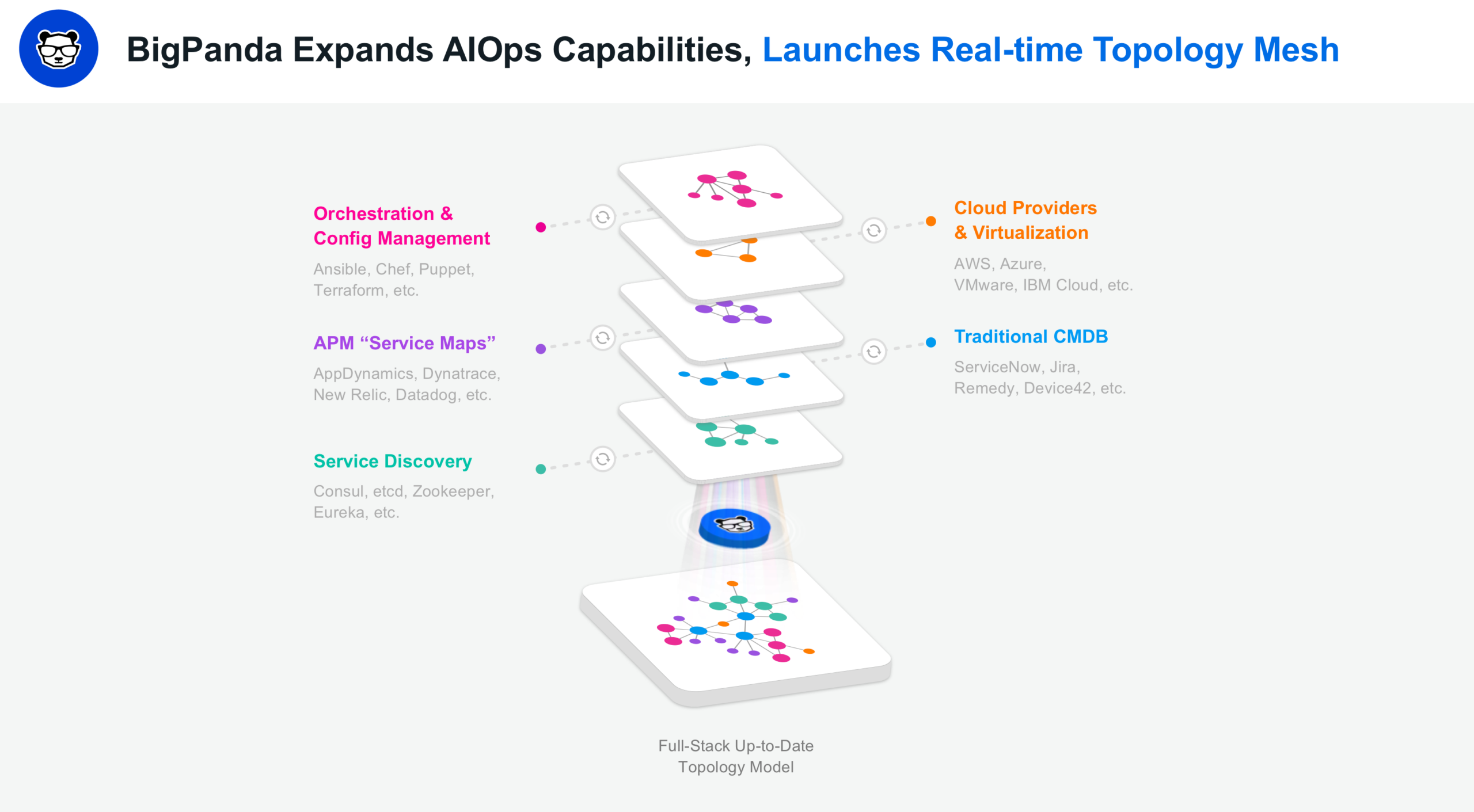
Given this – we asked ourselves – why should IT Ops, NOC and DevOps/SRE teams be forced to depend on a limited view of their application and service topologies – a view gleaned from just one source in most cases, handicapping their ability to get to the accurate root cause of outages and incidents quickly and easily?
So our Product and R&D teams set out to solve this by
(a) collecting topology data from all enterprise topology tools and feeds,
(b) stitching it together in real-time, from enterprise Service Discovery tools, Orchestration tools, Cloud Providers and their Virtualization tools, their APM tools, and even their legacy CMDBs, to create a full-stack topology model, and
(c) keeping it up-to-date at all times.
The result is our brand-new Real-Time Topology Mesh.
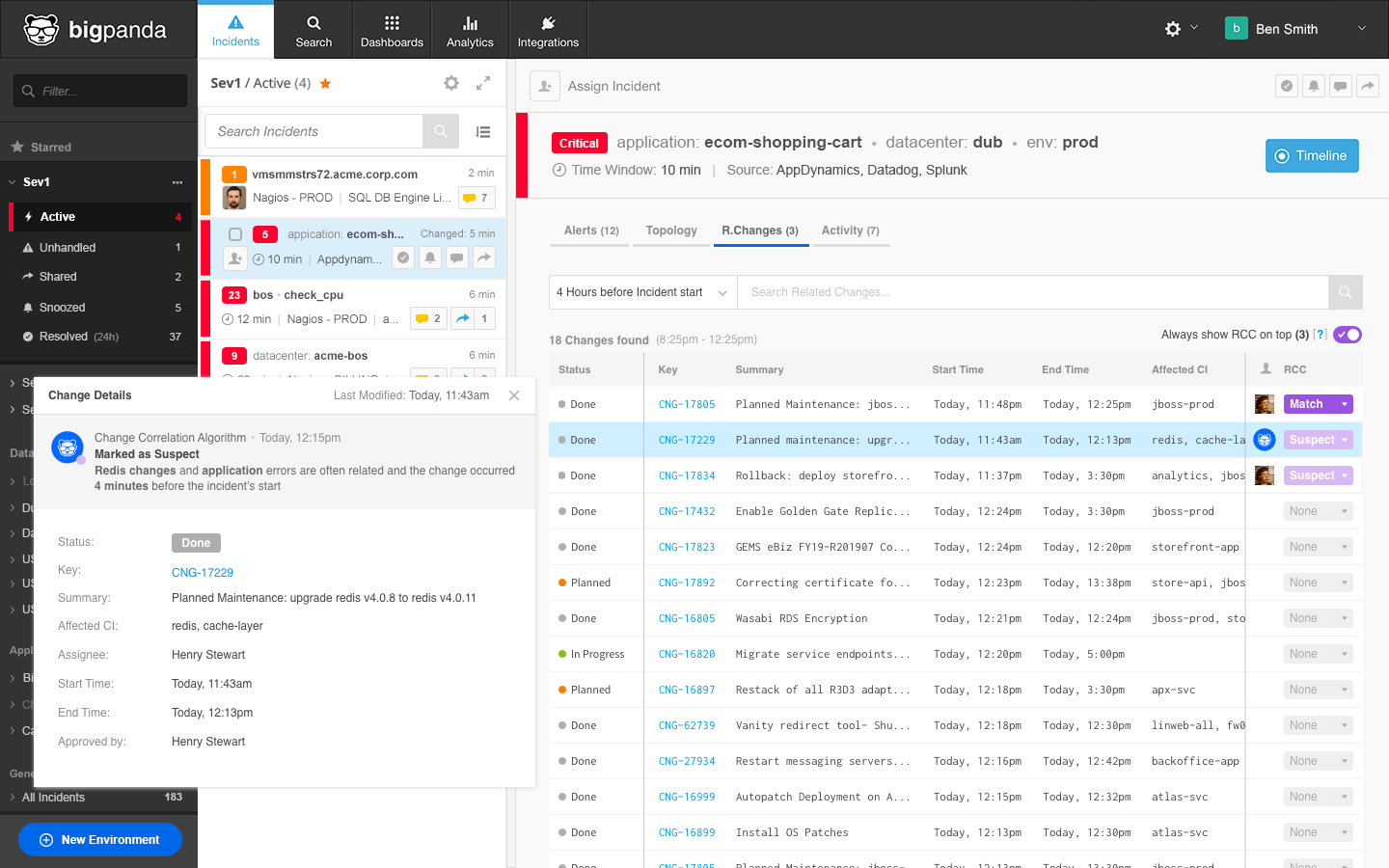
What Changed? Now You Can Get a Real-Time Answer!
The Root Cause Changes feature helps IT Ops, NOC and DevOps/SRE teams get a real-time answer to the “what changed?” question.
By putting this at the fingertips of these teams, outages and incidents no longer have to be prolonged and painful.
When these teams look at an incident in the BigPanda Ops console, with just two more clicks, they can see a list of all related changes and look at the suspect change flagged by BigPanda’s Open Box Machine Learning technology.
If it’s the right one, users can tell BigPanda that this is the correct (matched) change and then immediately act on it. Or they can share this information with the appropriate service desk team, or another escalation point, for immediate action.
Users can also use their expert or domain knowledge and improve BigPanda’s machine learning-based incident-change matching abilities by manually flagging specific changes surfaced by BigPanda as the ones behind an outage or incident.
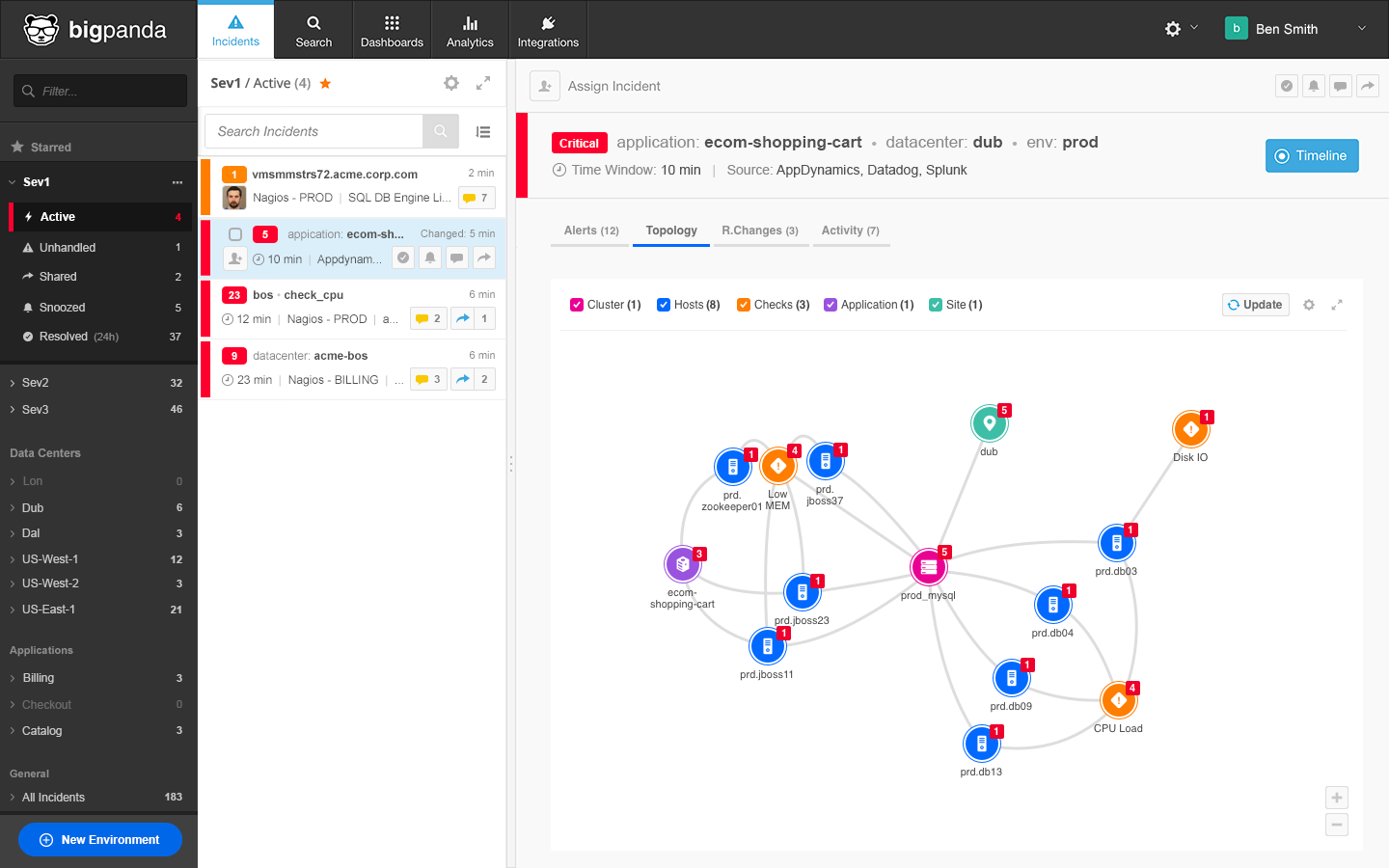
What Does The Real-time Topology Mesh Let You Do?
The Real-time Topology Mesh lets users do several things inside fast-moving IT stacks.
While identifying the root cause of outages and incidents quickly and easily in these fast-moving IT stacks is a major benefit, there are other benefits too, across the incident management lifecycle:
- Detect outages and incidents faster.
- Understand the impact of outages and incidents better,
- Visualize incidents, and
- Route outages and incidents to the right teams for rapid resolution.
Together, these features can help the unsung heroes of IT – IT Ops, NOC and DevOps/SRE teams – detect, investigate, and resolve outages and incidents in fast-moving IT stacks more easily, and confidently, than ever before.
Sound interesting?
If this sounds interesting, here are a couple of things you can do.
Watch our short explainer video and get a high-level understanding of how BigPanda consumes all three datasets – alerts, changes, and topology – to help you rapidly detect, investigate and resolve outages and incidents.
You can also watch another short explainer video focused just on how our Root Cause Changes feature works.
Get in touch with us to schedule a demo.
We hope to hear from you soon…thanks for reading!




