




BigPanda transforms IT major incident management with customizable AI workflows that eliminate coordination work and cut MTTR in half.
Standard
The BigPanda AI Incident Assistant allows enterprises to respond to incidents at machine speed, dramatically improving operational efficiency and delivering exceptional service reliability.

Learn how agentic AI can help modernize IT change management by providing visibility, control, and automation where needed.

Fragmented systems overwhelm SREs. Agentic ITOps uses AI agents to correlate signals fast, deliver context, and speed incident response.
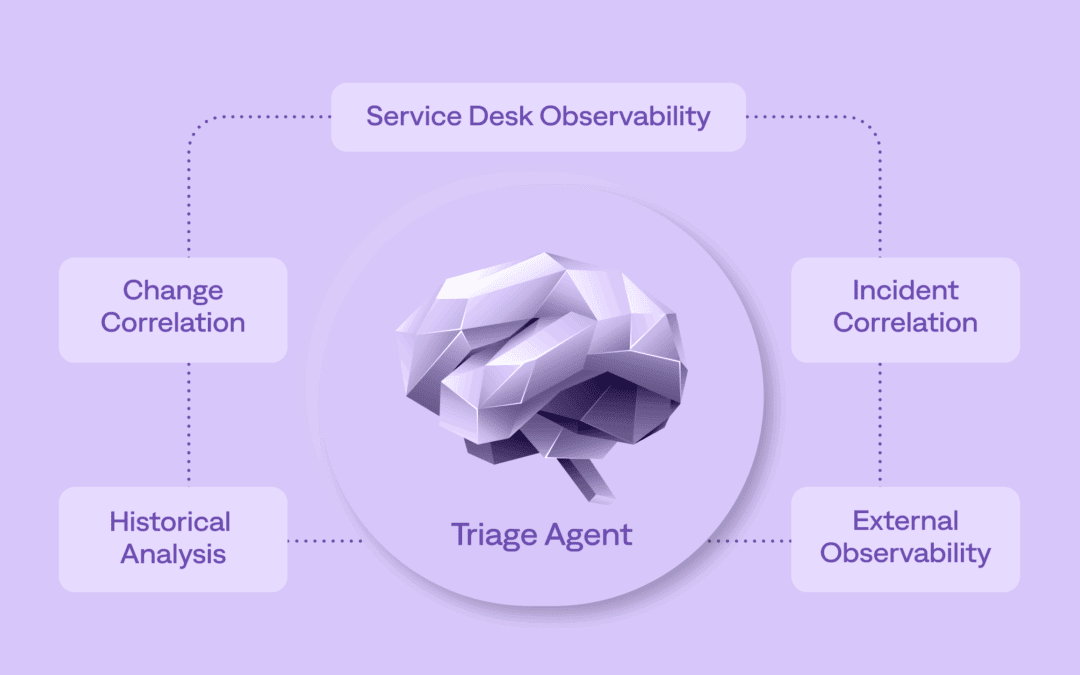
Triage Agent for ITOps gathers relevant context to automate investigation and improve triage, and reduces unnecessary escalations.

The recent Cloudflare outage served as a stark reminder of how fragile the global digital ecosystem can be due to a single point of failure. In a matter of minutes, thousands of websites that rely on Cloudflare’s CDN, from Fortune 500 brands to SaaS platforms and consumer apps, went offline for hours. The business impacts […]
When external providers fail—whether it was CrowdStrike outage last year, AWS outage last month, or the Cloudflare DNS outage yesterday—the symptoms inside your environment often look like internal issues: timeouts, login failures, API errors, service degradation, or sudden spikes in dependency-related alerts. It’s natural for teams to start searching through their own infrastructure first, but […]

BigPanda acquires AI SRE leader Velocity to accelerate agentic ITOps—automating detection, boosting resiliency & transforming enterprise IT with reasoning-based AI.

IT infrastructure resilience is essential for any modern IT environment. Downtime is expensive. Beyond the stresses of day-to-day operations, you want to be confident that your IT systems will continue functioning during service disruptions, hardware failures, or natural disasters. Agentic ITOps can help ensure a reliable, resilient IT infrastructure environment. These systems use agentic AI […]

Learn how to quantify the value of the BigPanda platform and read how customers justify their IT investment

Agentic ITOps from BigPanda deliver the promised value of AIOps by automating incident detection, triage, and resolution to cut costs and boost service reliability.

BigPanda has launched IT Problem Management within its AI Incident Prevention product, enabling enterprises to predict and prevent recurring incidents at scale.

BigPanda and Jira Service Management are announcing an integration that delivers visibility to proactively identify and resolve incidents.

Read how BigPanda helps address tool sprawl, reducing costs and optimizing operations

BigPanda was recognized in 10 Gartner Hype Cycles in 2025, showcasing leadership in Event Intelligence Solutions and IT operations innovation.

New ADR features help L1 teams achieve faster detection and utilize automation for more accurate diagnosis and triage.

BigPanda introduces agentic AI for ITOps. Our platform automates incident detection, triage, and resolution to cut costs and boost service reliability.

At BigPanda, HEART represents our core values, which guide how we work, collaborate, and serve our customers daily. HEART stands for Hunger, Extreme ownership, Active transparency, Relentless customer focus, and one Team (HEART). We strive to live by these principles in every project, meeting, and interaction. Each year, we celebrate the remarkable Pandas who embody […]
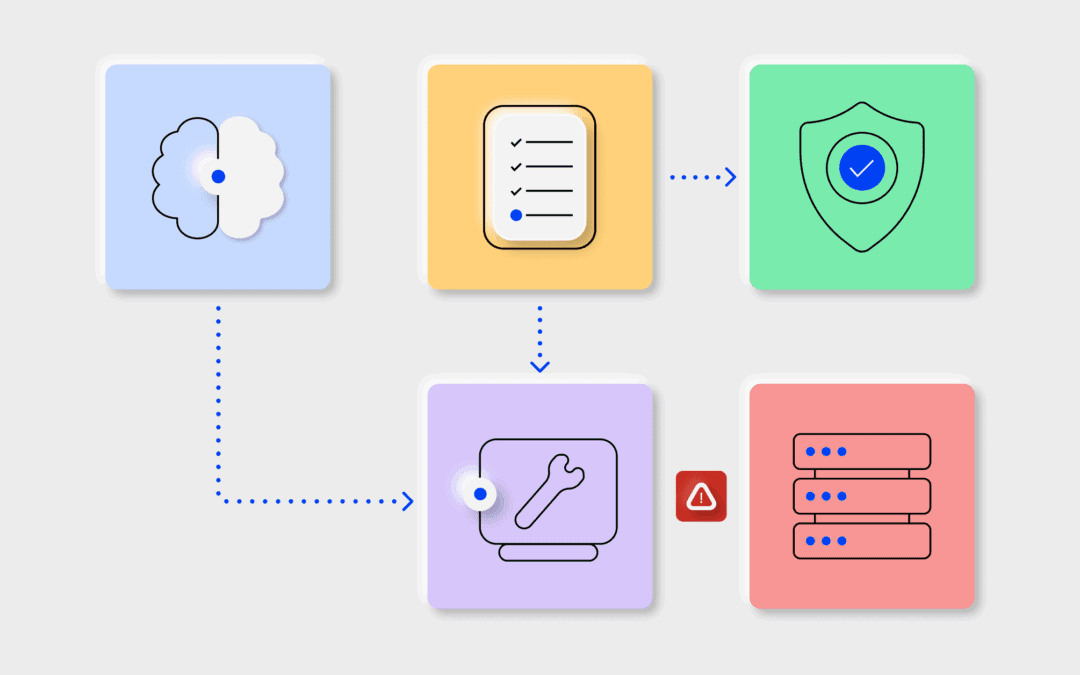
BigPanda AI Incident Prevention proactively mitigates IT change management risks. Designed to prevent incidents before they occur.

Learn what observability is and how it empowers IT teams to gain deep insights into system behavior and incident management.

Learn the top findings from the BigPanda Monitoring and Observability Tool Effectiveness for IT Event Management.
Agentic AI can be applied to ITOps to automate incident detection, triage, and resolution, cut costs, and boost service reliability.

Say goodbye to fractured, siloed data. GenAI can transform all unstructured data sources into usable fuel for agentic IT operations.
Last week saw several huge milestones for BigPanda. We launched the BigPanda agentic IT operations platform, a sweeping evolution of our product offerings. As part of this launch, we also introduced two new AI solutions, BigPanda AI Detection and Response and BigPanda AI Incident Assistant. These powerful new capabilities bring agentic AI into IT operations, […]

What is an AIOps platform? Discover how they leverage AI and automation for smarter IT operations. Uncover their benefits and use cases.
IT operations have reached a breaking point. Hybrid cloud and modern software architectures have led to unprecedented increases in the scale, complexity, and fragmentation of IT infrastructures. In their attempts to manage this complexity, enterprises invest billions into observability tools, IT Service Management (ITSM) platforms, and outsourced Managed Service Providers (MSPs). Despite these investments, enterprises […]

Fragmented tools, teams, and processes are more than an inconvenience in IT Operations. They are major bottlenecks that hinder collaboration, slow down incident resolution, and jeopardize customer experiences. In a recent webinar, Adam Blau, VP of Product Marketing at BigPanda, and Britton Starr, a Technical Account Manager, shared their insights into the operational chaos plaguing […]
Learn recommendations from Gartner® to reduce the impact of IT incidents on hybrid cloud environments with an AI-powered approach to ITSM.

BigPanda was named a Representative Vendor in the 2025 Gartner® Market Guide for Event Intelligence Solutions. BigPanda applies AI to augment, accelerate, and automate IT operations and incident management.

BigPanda was named as a Representative Vendor in the 2025 Gartner® Market Guide for Event Intelligence Solutions. BigPanda applies AI to augment, accelerate, and automate IT operations processes.
AI-Powered Event Management from BigPanda transforms siloed IT data into insights for faster detection and triage.

Eliminate recurring incidents by identifying trends and enabling proactive action to reduce downtime and improve IT efficiency.

IT infrastructure monitoring is a systematic process of observing, collecting data, and analyzing the performance, availability, and health of IT components.

With BigPanda AIOps, Sony accelerates incident response, improves efficiency, and enhances the work-life balance of its IT teams.

Enhance ITOps and ITSM team efficiency across the entire incident lifecycle with BigPanda’s newest feature updates.

Learn how AIOps helps financial institutions improve operational resilience and incident management, gain visibility into their ICT, and maintain DORA compliance.

When your IT team is overwhelmed with tickets, dealing with shadow IT, and always putting out fires, it can feel frustrating. That’s where IT Service Management (ITSM) comes in. ITSM provides a plan to deliver reliable IT services. It helps teams focus on what matters most: achieving business success. It encompasses everything from handling incidents […]

Explore how ServiceNow’s CMDB functions and discover the transformative power of AIOps in modernizing IT service management.

BigPanda helps MSPs scale through technology and enhance and differentiate their service offerings to stay competitive.

Hear from working parents at BigPanda, where balancing family and career is supported through understanding, flexibility, and empowerment.
Discover how to improve your ITIL incident management for swift issue resolution, minimal downtime, and continuous service improvement.

Over the next 10 years, enterprise CIOs will be judged primarily on how effectively they incorporate AI into ITOps and ITSM processes.
Learn how CIOs and ITOps teams can adapt their organizations to survive crisis-related challenges and be well-positioned for the long term.

The BigPanda Community offers exclusive insights and resources meticulously crafted to empower your IT Operations (ITOps) and AIOps journey.

Learn about the three pillars of observability—logs, metrics, and traces—and how they work together to provide full visibility into your IT systems.
Synthesize complex data with Ops Centric AI. Turn fragmented IT noise into high-quality, actionable insights for fast IT incident management.

Learn the key insights the BigPanda team learned at the 2024 Gartner® IT Infrastructure, Operations & Cloud Strategies Conference.

AI-Powered Incident Management from BigPanda turns siloed data into situational awareness for faster IT incident investigation.

Uncover how AIOps can enhance your observability tools by automating tasks, streamlining alerts, and speeding up incident resolution.

BigPanda Advanced Insight uses AI to analyze complex data so responders can triage IT incidents faster and improve service reliability.
Learn the value of data enrichment in ITOps. Understand how enriched data transforms raw information into actionable insights for smarter incident management.

The BigPanda Community connects you to a network of ITOps and AIOps professionals. Join today to get exclusive access to expert insights and advice.

Successful AIOps adoption relies on organizational change management to support team alignment, scalable implementation models, and focus on ROI.

Learn how BigPanda AIOps unifies ITOps and incident management, delivering context for efficient resolutions and improved reliability.
A recent report from EMA research highlights the benefits of AIOps for IT operations (ITOps) and IT service management (ITSM) teams.
Generative AI is changing the game in IT services. Learn six ways IT teams benefit from GenAI for smoother, faster incident resolution.

Data integration improves ITOps with actionable insights to enable faster detection, better collaboration, and improved reliability.

Join the BigPanda Community to gain access to fast answers, search across all BigPanda resources, and get the latest product updates all in one place.

AIOps optimizes NOC performance by automating incident detection, prioritization, and resolution to improve service availability.
AI-powered IT operations (AIOps) enhance observability tools by transforming IT noise into actionable insights to improve performance.

New features in BigPanda help ITOps and ITSM teams streamline incident response and ensure high service availability.
From new graduates to those making career transitions, early-in-career professionals bring unique perspectives and energy to BigPanda.

Operationalizing AI is essential to improve the efficiency of IT operations and remain effective in increasingly complex IT environments.

Create an effective incident response plan to protect service operations.

Build the skills you need to seamlessly integrate BigPanda with ServiceNow to improve incident management.

Five core incident response phases are part of a structured approach to managing and addressing disruptive IT events to protect your organization.

The BigPanda volunteerism program strives to support the communities where we work and live.

Runbooks bring order and organization to ITOps, offering concise instructions for teams to respond to critical incidents effectively.

Stay ahead of IT challenges with AIOps monitoring. Gain valuable insights into the latest trends, tools, and best practices for efficient operations management.

Explore how to navigate generative AI challenges in IT operations and discover four key criteria for choosing the right AI copilot.
Transform future IT operations and incident management using AI copilots to enhance operational efficiency and speed incident resolution.

Learn the critical steps to achieving full-context ops that transform alerts into actionable insights and maximize IT efficiency and system performance.

AI, ML, and automation can help IT teams accelerate innovation to streamline processes, reduce manual work, and improve service delivery.

By adopting an AIOps strategy, you can enjoy increased efficiency, quicker incident resolution, and more effective collaboration.

BigPanda AIOps delivers 80% noise reduction in the first eight weeks, providing tangible value for IT operations and service-desk teams.

Know who to collaborate with in the IT organization to support the adoption of new AIOps tools and processes.

Best practices for addressing the organizational change-management challenges that come with implementing new AIOps tools and processes

Six ways to use AIOps copilots to improve ITOps and incident management team efficiency, share knowledge, and deliver immediate value.

BigPanda customers shared their best practices and learnings from addressing the challenges brought on by the July 2024 global outage.
Infrastructure data trapped in silos — and a lack of operational context — creates delays and unnecessary stress for ITOps, observability, and ITSM teams.

BigPanda University courses cater to all skill levels. Learn whenever and wherever you want, making it easier to enhance your skills.
Build a custom view in the BigPanda Incident Console to reduce MTTR and more effectively triage and resolve incidents.

Surface the context you need within your event-management workflow using new updates in the BigPanda platform.

AI-powered copilots can troubleshoot active incidents in real time for ITOps and ITSM to identify cause, impact, and resolution steps.

How the BigPanda documentation team is improving the support experience — and the ability to deliver it — with content reuse.
BigPanda integrates with ServiceNow to give ITOps and ITSM teams the insights to proactively identify, respond to, and remediate incidents.
AIOps uses generative AI to create a unified view of IT incidents to help operators resolve outages faster and improve service availability.

On-demand: Normalize event payloads into a consistent taxonomy and enrich alerts with relevant context within the BigPanda platform.

Maddie Serembus joined the BigPanda marketing team for a summer internship as she works toward her studies in marketing and sales at University of Delaware.

Build off your foundation of actionable alerts and normalized data by implementing AI to improve MTTR.
As you work toward full implementation of AIOps, focus on event correlation and best practices to create more actionable incident data.

The lines between ITSM and AIOps are blurring. Gartner Hype Cycle for ITSM, 2024 highlights this shift and changes in AIOps service delivery.

Reduce alert noise across disparate monitoring sources to gain centralized visibility and leverage AI for IT operations.
Event intelligence solutions or AIOps platforms? What does the new terminology from Gartner mean for you and your IT operations?

AIOps gives ITSM and ITOps teams a unified view of incidents and the IT environment, facilitating the key outcomes of ServiceOps.
Getting value from AIOps requires understanding their use cases. Get insights from Gartner® research.

Empower ITOps and ITSM with context. Identify incident root causes based on recent changes for swift, accurate resolution.

BigPanda CIO Jason Walker joins financial services podcasts to talk about using AIOps and GenAI to improve IT incident management.

In honor of International Women in Engineering Day 2024, we explore the inspiring stories of women engineers.

Set a strong foundation with event management to reduce noise and unify disparate data sources. Mature into more advanced AIOps use cases including GenAI.

Meet Caitlin Davis, BigPanda’s new Chief People Officer. Discover her vision and plans for fostering a dynamic and thriving workplace culture.

Each year, we recognize outstanding employees at BigPanda who go above and beyond to demonstrate our core values in their work and leadership.

Accomplish fast, reliable incident root-cause discovery with AIOps and significantly reduce mean time to resolution (MTTR) beyond manual capabilities.

Advances in generative AI are transforming IT operations modernization. Use full-context operations to improve service availability and reduce downtime.

Context is imperative for informed decision-making when facing obstacles like data fragmentation and disparate sources. AIOps delivers.

Outages can cost your organization up to $25,000 per minute. AIOps and automation can simplify, enhance, and shorten incident triage, leading to faster MTTR.

IT outages cost $14,056 per minute on average. What’s driving the increased costs? How can you use AIOps to reduce their frequency, duration, and impact?

BigPanda 24 brought together ITOps leaders from across industries to discuss the future of AIOps and IT operations. CEO Assaf Resnick shares his thoughts.
Reduce manual incident investigation, identify actionable insights, and speed resolution using relevant historical data from similar incidents.
Improve uptime and efficiency. With full-context IT operations management, you get the big picture of incidents every time, from every angle.

The BigPanda AI-powered copilot is the first to leverage all sources of human-generated, institutional knowledge for AI-powered incident response.
Full-context operations provide the data, insights, and processes to make every stage of incident management faster, more consistent, and sustainable.

Discover the power of AIOps in transforming IT infrastructure monitoring into a proactive strategy.

Revolutionize IT service assurance by using AI to enhance operational performance, predict issues, and automate responses.
Elevate efficiency using advanced IT monitoring software and AIOps. Intelligent insights ensure seamless IT operations for sustained business success.

Discover how to set up BigPanda Open Integration Manager, alert normalization, and mapping enrichment to maximize your alert management.

Use AIOps to help financial services ITOps teams tackle common challenges and ensure the availability of always-on financial solutions.

Discover the power of self-healing IT. Learn how to overcome IT automation challenges to automate issue resolution, reduce downtime, and boost reliability with BigPanda and Red Hat Ansible.

Learn the strategies and steps to improving your alert payload. See how better alert data handling helps to improve your AIOps alert correlation.

Discover how ServiceNow AIOps uses artificial intelligence and transforms incident management for smarter IT operations.

Don’t let monitoring anomaly detection cause you stress. Learn how your AIOps can help speed incident resolution with observability anomaly detection.

Our AIOps predictions focus on what’s next with generative AI, integration, automation, incident management, job roles, and market trends.

Learn how the BigPanda Root Cause Changes feature optimizes incident management by linking incidents with relevant changes to reduce resolution time greatly.

BigPanda University is a self-paced learning hub offering hands-on experience, a comprehensive curriculum, and certifications for peak AIOps proficiency.
Explore strategies for optimizing cloud infrastructure management, balancing observability and monitoring, cost, and performance for peak efficiency.

Improve your organization’s incident response capabilities with incident management software. Learn how to find the ideal solution for your needs.

From events to alerts to incidents: Use this simple guide to navigate often misunderstood IT operations terminology.

Discover the new BigPanda Unified Console with timeline views, data exports, AI insights, collaboration, incident tags and environments, and UI.

Application monitoring is indispensable to safeguard against disruptions and enhance user experience for modern organizations.
BigPanda’s Conor Castronovo, head of analyst relations, shares his findings from the Gartner IOCS conferences in London and Las Vegas.

Explore ServiceNow Incident Management: its importance, features, and benefits. Plus, learn how Autodesk reduced incidents by 69%.

Discover how to begin your IT operations automation. Learn how to streamline workflows and tasks, reducing costs and improving operational efficiency.

Event analytics help streamline operations, detect issues, and optimize system performance to enhance efficiency. See how IHG and Zayo are using it.
Discover what IT incident tracking is and why it matters. Gain strategies to select the right tools and improve system reliability.

Connect with BigPanda Gartner at IOCS 2023. Hear from our customers, meet our team, and learn how to get more value from your data with our AIOPs platform.

Ensure reliable ITOps with effective IT alert management. Discover how to implement and improve alert management for business continuity.
Discover what ServiceNow’s change management does, and how AIOps supports fast-paced IT with more insights for seamless change management.

Explore the basics of the PagerDuty incident response platform and how it integrates seamlessly with BigPanda for efficient IT operations.

Unlock IT efficiency with BigPanda Unified Analytics. See how to get end-to-end visibility, explore process improvement, and showcase value.

Discover the essentials of the observability tool landscape. Learn how to tame its complexity to improve IT system monitoring and cost efficiency.

Explore observability tool consolidation. Learn how AIOps streamlines tool usage, improves data, and reduces tool costs for IT systems.

Accelerate and automate incident response actions with Red Hat® Ansible® Automation Platform to focus on high-impact work.

Discover why ITOps needs intelligent alerts for efficiency and stability. Learn how applying AI/ML to alerts means smarter IT management.

Discover ServiceNow IT Operations Management. Learn how ITOM enhances operational efficiency, its functionalities, and how to optimize it with AIOps.

Learn how IT Operations Analytics improve system reliability and availability. Become proactive with integrated and unified data. See use cases and KPIs.

Learn how AIOps enhances cloud observability, monitoring, and visibility for peak application performance.

Explore AIOps’ impact on CMDB modernization and business outcomes. Unlock greater IT accuracy and insights with AIOps and CMDBs.
DevOps practices in software development have revolutionized the way updates are released. However, many companies entrenched in ITIL practices find it challenging to seamlessly integrate with the DevOps practice of Continuous Integration and Continuous Delivery/Deployment (CI/CD). This is because ITIL focuses on stability, which suits older systems, while DevOps is ideal for modern setups with […]

How does MTBF predict system reliability and uptime? Learn how it relates to MTTR and how to maximize it for seamless operations.

IT leaders are thrilled about the potential of Generative AI for IT Operations. But they also want to know how it works, why it works, and what it will do for them before taking the leap and adopting this new technology. Allow me to share my perspective on the hype and the truth behind generative […]

Finding the root causes of IT anomalies can be challenging, but the rewards are worth it. By identifying the root cause or causes of an incident or critical failure, response teams can resolve incidents faster and determine the best steps to avoid having them recur. This can drive down both the frequency of service interruptions […]

Discover how root-cause analysis and automation can help fix root causes, improve processes, and detect issues early.

Today, the majority of organizations operate under a hybrid cloud structure. Due to this, operations are consistently met with daily infrastructure and software changes and updates, which are also the primary cause of incidents and outages. Long gone are the days when a tech stack could be represented by a single dependency model. Microservices, CI/CD, […]

How BigPanda’s customer education resources can help your organization navigate change through the AI Revolution.

Discover what’s driving the analyst hype behind BigPanda’s AIOps innovations.
Transetyx quickly configured six standard monitoring integrations for a 96% noise reduction.

CEO Assaf Resnick explains why Dell’s acquisition of Moogsoft is proof of the ITOps AI revolution.

Discover how Datadog and BigPanda make observability and AIOps platforms function better for developer teams.

Deliver greater situational AIOps awareness at a lower cost with the combined impact of BigPanda and Cribl.
IT response teams find themselves battling against an overwhelming onslaught of incidents. Frustratingly long response times, challenges with prioritization, and the relentless pursuit of root cause are formidable adversaries that test even the most skilled teams. I remember customers’ electrifying anticipation with AI and automation a decade ago. They hoped AI could be used to […]

BigPanda’s experts share their cost optimization best practices. Discover how strategic IT cost optimization can reduce spend for software licensing, alert noise, ticket creation, and more.
Discover how applying AIOps to observability revolutionizes source monitoring at every stage.

BigPanda transforms millions of events into a small number of actionable alerts, no matter where they originate. Watch this video to learn more.

Beyond being the right thing to do, fostering inclusivity in the workplace empowers employees to show up fully as their authentic selves. “BigPanda is the first shop where I have openly identified as non-binary because I felt safe enough to,” said one employee. And considering how much of our life we spend working, BigPanda knows […]

Sony Interactive Entertainment introduced alert quality standards to build high-performing IT systems that reduced manual processes and costs.

A new era for incident management is upon us with the introduction of large language models and IT operations.

Workflow Automation and AIOps streamlines incident management and improves team collaboration. Learn how Abbott’s ITOps team overcame legacy system challenges with BigPanda.

BigPanda brings all your observability, topology, and change data into a single console. Read this best practices guide to learn how to get started.

In light of the macroeconomic environment, BigPanda is announcing that we are streamlining and restructuring to better execute on our mission.

The average cost of an IT outage is $12,900 per minute. Learn which steps IT Operations teams can take to minimize an outage’s impact.

High-quality alerts are fundamental to optimizing an ITOps organization. Learn how alert intelligence can add context and improve the effectiveness of IT alerts.

Every year, BigPanda recognizes employees that demonstrate our core values in their work every day. Read more to see which charities we donated to on their behalf.

Data is power, especially in optimizing IT operations. Creating and reporting the right set of metrics can help IT teams improve efficiency.

Learn how an insurance company reduced IT alerts from 6 million to 50,000 by tracing alerts with BigPanda.

Automating incident management helps more efficiently detect and resolve critical incidents. Learn more about the best practices for IT incident management.

Pragmatic AI has real value for ITOps teams. Learn how AI and ML can assist at any stage of the incident lifecycle.

Digitization of brick-and-mortar stores isn’t new—it’s evolving. Learn how ITOps teams can support this shift.

To celebrate International Women’s Day, female leaders at BigPanda share their experiences as women working in the tech industry.
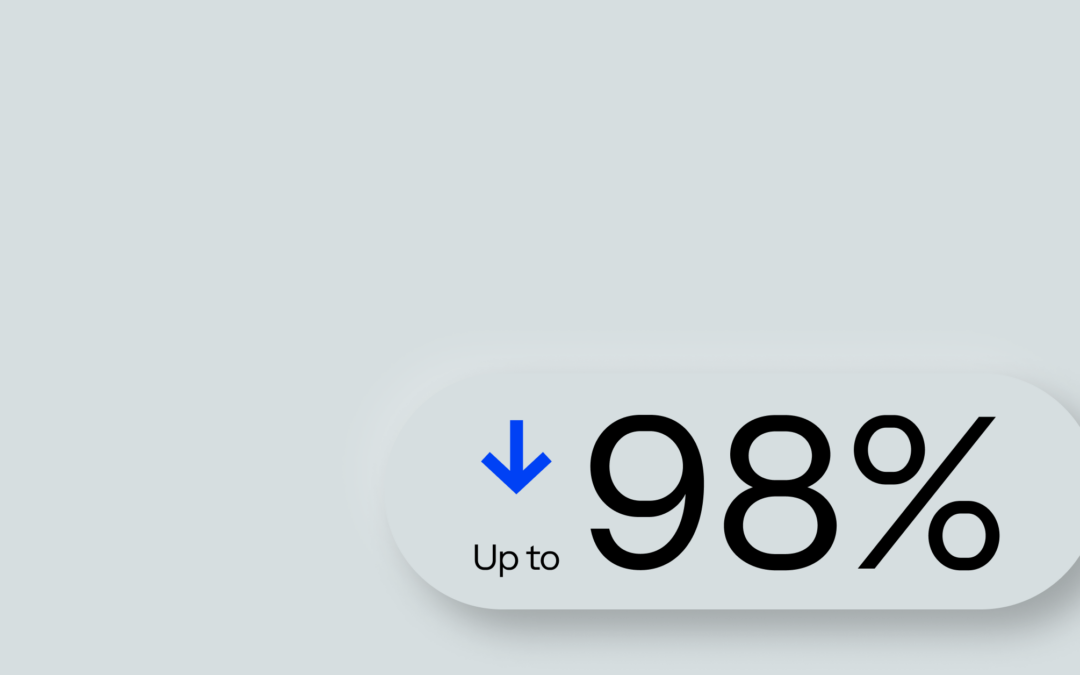
Dramatically reduce IT noise with innovative alert correlation, powered by AIOps and BigPanda.

Most ITOps teams use a traditional, on-prem tech stack and often two or more cloud infrastructure stacks.

From the rise of AI to global trends in the economy, discover four key ways that tech is set to evolve in 2023.

Confidently building and defending your ITOps budget is crucial to getting the resources you need. Learn three helpful strategies to set yourself up for success.

What will 2023 look like for the industry? Our panel of industry experts share some insights to help you navigate the choppy waters.

Travis Cox, our Regional Vice President of Sales, shares what Black History Month means to him.

BigPanda University was named a finalist for the Awesomeness in Customer Education (ACE) awards presented by CustomerEducation.org.

BigPanda Sales Engineer Kevin Wood shares why he decided to join the BigPanda team.

The past decade has seen organizations embrace AI and data analytics at scale. In 2022, IBM found that 35% of organizations have embraced AI—a 4% increase from 2021. The trend of AI adoption will continue to play out in the next several years across virtually every organizational function. At the vanguard of this movement is […]

CDI experienced success with BigPanda’s products, first as a partner and now also as a customer.

In 2022, BigPanda made several product updates to help you quickly adopt AIOps and increase uptime, efficiency, and velocity.

Sanjay Chandra, Vice President of IT at Lucid Motors shares how to scale the NOC globally using AIOps technology, not people.

There’s no cure for IT outages. However, AIOps can help. Valerie O’Connell, Research Director at EMA shares more.

Here’s everything you need to know about CI/CD pipelines but were afraid to ask.

Discover how BigPanda transforms the IT data tsunami into actionable intelligence and automation, enabling incident response teams to increase uptime, efficiency and velocity.

The success of CI/CD depends on collaboration between IT Operations managers, DevOps engineers, and other stakeholders. Learn why CI/CD is important and why.

Discover how to create custom inbound alert integrations through the configuration of a generic, out-of-the-box inbound integration rather than using custom code.

Do you know the difference between CI/CD and ITIL? Read this blog to find out which approach is best for your needs.

Joe Schramm, VP of alliances and channels, comes to BigPanda with the goal of forging mutually beneficial partnerships. Learn more.

Automation, when implemented correctly, can completely transform your ITOps. Here’s what you need to know.
![[Report:] The true costs of modern IT outages](https://www.bigpanda.io/wp-content/uploads/2022/11/blog-real-outage-costs-sm-1080x628.jpg)
BigPanda wanted to uncover the true numbers behind outage costs and it’s more than you think. Here’s what we found.

Learn more about how simple the Email Parser makes processing important data from your emails.

Working in the NOC can be very scary. Here are some spooky tales from the NOCside.

How much do you know about AIOps and event correlation? In this post we explore everything from its origins to current state-of-the-art techniques and how it fits into integrated service management.

Stakes never have been higher for ITSM in healthcare. Learn more about what’s working and what’s not.

In this blog, we’ll look at event types, use cases for event correlation and approaches that organizations can use to get the most out of this valuable tool.

Erika Streib, new Enterprise Account Executive shares her path as a #WomanInTech and why she chose BigPanda to be her home.

The goal of AIOps in event correlation is to accelerate the identification and resolution of IT issues. Learn more here.

Learn key takeaways from the latest Gartner AIOps Platform Market report to reveal the clearest path to showing value for AIOps.

BigPanda was selected to receive the 2022 Tech Cares Award from TrustRadius. Learn more about how culture drives success.

BigPanda’s enhanced Unified Analytics was designed with our customers’ input. Learn more here.

BigPanda’s Open Integration Manager and Email Parser aim to streamline integrating these kinds of monitoring tools with the BigPanda platform. Learn more.

Discover the ease of integrating the ticketing and messaging tools with BigPanda.

Integrating all of your monitoring alert sources is quite a task. Large enterprises often struggle to aggregate millions of data records from dozens of monitoring, change, and topology tools in real-time. Filtering out the noise and prioritizing the most important alerts are crucial to a team’s success. BigPanda makes it simple to integrate with any […]

With a start-up background, Omri was excited about the possibilities that a company like BigPanda could offer, including working with a talented team of people.
For Guy, BigPanda was the perfect organization to bring his global IT as well as military experience and embrace his career aspirations with true flexibility.

Ben believes that he joined BigPanda at the ideal time, and he’s blown away by the camaraderie and professionalism of everyone he has met so far.

Nitzan’s favorite aspect of being a part of BigPanda is the excitement, motivation and inspiration of the team and their willingness to listen to ideas.

The amount of data volume and complexity within tech stacks is continuing to increase with no sign of slowing down. As a result, many organizations are facing significant challenges related to tool sprawl and the overwhelming amount of data that needs to be exchanged between all the different systems. The result is this new rapid […]

BigPanda is on the cutting edge of AI and IT, but it is also poised to make AIOps accessible to organizations of any size. Read more about our new chapter.

As an IT Ops exec, imagine your jubilation upon learning that after a year of hard work across your NOC, DevOps and SRE teams, you are able to automate incident response by 25%. You’re elated as you enter your CTO’s office to share this information, and their response is: “And your point is?” If that […]

AI and ML are great, but explainable AI and ML are better. Here’s what you need to know.

Insight Partners is a leader in working with scale-up companies that have existing product/market fit and can use our help establishing best practices for their businesses. But my specific focus is in developer-driven companies. I look for the best technical teams that are building products that developers love and adore. Not only did we find […]

Solution-oriented Olivia was looking for an exciting career change that aligned with previous experiences, and BigPanda offered the perfect opportunity to learn with a team.

Incident Search and Incident Actions are the newest capabilities for BigPanda self-service APIs. Learn more here.

Looking for a new career? Our VP of Global Sales, Matt Peloso shares why now is the time to join BigPanda.

The effects of BigPanda’s most recent round of funding—amounting to $190 million—will be reverberating throughout the company for years to come. And it’s not just BigPanda employees who have experienced a surge of enthusiasm in the wake of our Unicorn status. Our customers are thrilled at the prospect of more innovation from our team and […]

The BigPanda Value and Adoption team just launched a helpful blog series aimed at bettering your understanding of AIOps maturity. In this first installment, Craig Ferrara, VP of Value and Adoption, shares the importance of self-healing and how Level-0 Automation can transform IT Ops.

At BigPanda, we’re laser-focused on making life easier for IT Ops teams. Here’s how we are helping IT Operations teams keep up.

Each year, we recognize a handful of Pandas that truly went above and beyond to demonstrate BigPanda values in their every day. This year, BigPanda selected 13 recipients to be able to give back to a local organization of their choice. Many of the charities selected are close to these Pandas’ hearts and communities. As […]

At the beginning of the COVID-19 pandemic, we anticipated a slow-down in IT-related spending. In reality, the opposite occurred. Companies massively expanded their digital offerings using the same IT staff they’d had pre-pandemic, even as the teams lost access to many of their existing tools while working from home. This acceleration put immense pressure on […]

I am excited to announce today that BigPanda has secured $190 million in financing at a $1.2 billion valuation. This financing was led by Advent International and Insight Partners, together with our other existing investors. BigPanda is now officially a unicorn, and the clear leader in the rapidly growing AIOps market! Keeping the digital economy […]

Learn how Autodesk uses BigPanda’s Event Enrichment Engine to help reduce their IT noise by 95% and substantially enhance their root cause analysis capabilities.

From stay-at-home parent to professional services aficionado, Justin has been focused on growth from the start. BigPanda’s small-organization feel and close-knit community appealed to him.

Success of AIOps tools relies heavily on the quality of data fed to their AI/ML algorithms. BigPanda’s best-in-class Event Enrichment Engine offers cross-domain enrichment capabilities at scale to assure AIOps success.

We’re excited to announce the latest enhancement to our Event Correlation and Automation platform that assists responders in triage, one of the most painful parts of the incident management lifecycle. Introducing BigPanda Automatic Incident Triage.

Integration diagnostics and an enhanced ServiceNow integration: doubling down on rapid time to value
Introducing two new major BigPanda releases for even faster time to value: Integrations diagnostics, and an enhanced ServiceNow integration.

Introducing BigPandaU and its first offering: the Getting Started video series, where you can learn how to easily set up and start using BigPanda.

The 2 most important Gartner strategic 2021 tech trends for IT Ops, and how BigPanda can help realize them.

Learn how Expedia modernized operations on their complex and fastest-moving IT stacks, and why they chose the BigPanda AIOps platform to help them with their mission.

Leading analysts continue to acknowledge BigPanda’s leading role in the AIOps ecosystem – this time in EMA’s Radar Report on AIOps.

Monitoring modernization can be a daunting task. But following a few tried-and-tested methodologies can help ease the pain.

Learn how BigPanda’s Root Cause Analysis features allow you to embrace the chaos of modern, fast-moving IT environments.

Headed to Gartner IOCS in Las Vegas? We are too. Here’s where you can find us during the conference.

With over 80% of outages caused by changes, Root Cause Changes is a key element in IT incident resolution. See how our Beta customers used our newest capability.

Until now, IT Ops, NOC & DevOps teams didn’t have an easy way to understand “What Changed?” when dealing with outages. Meet BigPanda’s Root Cause Changes.

Many IT leaders are considering AIOps solutions in their quest to keep systems running 24x7x365. What should they be looking for?

The results of our AIOps survey are in. Here’s what 1300 IT Ops professionals say about the future of automation, AI & ML and their role in the enterprise.

This playbook from CIO Dive explains how AIOps tools can reduce IT noise, detect problems, surface probable root cause, reduce ticket volumes & slash MTTR.

Have an immature CMDB, or no CMDB at all? No problem, BigPanda can still correlate your alerts and drastically reduce your IT noise.

In this new whitepaper, noted industry analyst Nancy Gohring of 451 Research delivers an in-depth look into the future of AI & ML-enabled IT Ops.

You’ve just recovered from a critical application outage and your team is being asked to report on root cause and recommended remediation steps later this afternoon. Can you quickly analyze all the data, identify all the leading events, and discern which one was responsible for the cascading failure? Later that week, you are back to […]
IT operations teams have some of the most stressful jobs in IT. Keeping data centers online, servers running, enterprise systems functioning, and applications performing — all while responding to incidents and requests is hard work. While there are monitoring systems in place to provide visibility and change management practices that give IT some control over the […]

This is the first in a series of blog posts on Open Box Machine Learning. If you’re part of a large enterprise, you’re probably in the throes of digital transformation. If you’re in IT, you’re supporting your business by rolling out new services and apps weekly (or even daily). Meanwhile, your users expect 24×7 availability […]

It was a big week for BigPanda at the Gartner IT Operations Strategies & Solutions (IOSS) Summit, which was held May 15-17th in Orlando, Fla. More than the Big News we announced and our CEO Assaf’s presentation, we enjoyed more than 700 high-quality interactions at Gartner IOSS Summit with senior enterprise IT leaders. Gartner’s theme this […]

Any organization can be defined by its operating principles. These are the fundamental norms, rules and values that represent what is desirable and positive for the group. Having well defined principles can help an organization operate as a “community” with a shared understanding of what is right and what is wrong. It’s key that these […]

BigPanda exhibited and moderated a customer success panel at Gartner’s big IT Infrastructure, Operations Management & Data Center show in Las Vegas last month. The Gartner I&O Conference is action-packed, so it’s taken me awhile to digest all the great information and insights I gathered there. Gartner’s influence in the enterprise IT operations market is undisputed. […]

Join our up coming live webinar video meeting to see how BigPanda works in real life application

Part 1 of this series defines algorithmic alert correlation and how it works. The term “algorithmic” describes how data science applies machine learning techniques to solve alert storms, aka alert floods. There are two flavors of machine learning currently being applied to this problem: one is “black box” and the other, “open box”. BigPanda applies open […]

The IT Operations tool stack is becoming exponentially more complex. This requires the utilization of a breadth of diverse monitoring tools in order to quickly detect and ultimately resolve critical issues before they can inflict real damage on the business. Most large enterprises already have a host of preferred monitoring tools installed and working. It […]

In his research note “Four Steps to Turbocharge Your Major Incident-Handling Capabilities”, Gartner analyst Kenneth Gonzalez makes a compelling argument for why enterprise IT service operations teams should upgrade their incident management workflow processes. Here’s BigPanda’s perspective on the topic. The Real Challenge: Most NOCs Aren’t Automated Most enterprises are undergoing some form of digital […]

What a week! Our team spent 5 days in Orlando last week, representing BigPanda at both Gartner’s IT Operations Strategies and Solutions Summit and ServiceNow’s Knowledge17 conferences. Here’s our wrap up on Gartner IOSS. Hundreds of enterprise IT leaders gathered in at the Hilton Orlando this past week to learn how IT can take advantage […]
Alert Correlation Platform Continues Growth Trajectory Fueled by New Customer Acquisitions and Partnerships PALO ALTO – May 17, 2016 — BigPanda, the Alert Correlation Platform that turns the huge volumes of IT data and alerts into consolidated insights for businesses, today announced that it has added $5 million to its Series B financing round for […]


For many IT and Ops teams, Nagios is both a blessing and a curse. On the one hand, Nagios gives you near real-time visibility into the inner workings of your IT infrastructure. But on the other hand, Nagios can generate so many alerts that it’s impossible for any single person (or even any team) to keep up.
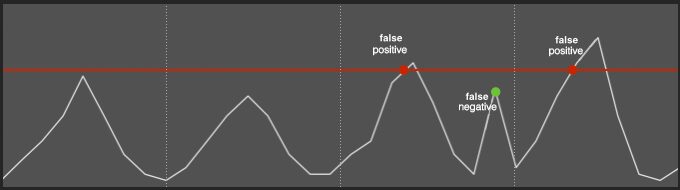
Anomaly detection for monitoring has been a trending topic in recent years. And while the math behind it is fascinating, too much of the discussion has revolved around histograms, moving averages and standard deviations. More discussion needs to happen around its practical applications, and for that reason, this practical guide to anomaly detection will attempt to provide an actionable overview of current off-the-shelf anomaly detection tools.