




Can enterprises move fast without breaking IT?
Updated: May 6, 2021
Category: Enabling the Business
Author: BigPanda
In one of our recent webinars we discussed a challenge in digital transformation that is top of mind for many IT Ops leaders: how to actually transform with the least amount of pain… Following are the highlights of that discussion, also recently published in an eWeek article. Or if you prefer – you can also watch the webinar on-demand here.
No matter how tired people are of the term “digital transformation”, it still represents an imperative strategy for enterprises wishing to survive in today’s dynamic business environment, let alone see growth and increased market value. Companies wishing to reduce operating costs, improve their performance and increase their business velocity MUST transform.
For IT Ops, this often means the following:
- Migrating to the cloud or creating hybrid-cloud architectures
- Modernizing legacy applications
- Embracing automation and AI through AIOps initiatives
- Shifting to DevOps / SRE models – autonomous, decentralized teams that are product-focused
- Shifting to remote IT operations (since last year)
We all know that the current pandemic has greatly accelerated this transformation, but new survey data from McKinsey starkly illustrates the scale of change. In 2020, IT operations teams everywhere struggled with the gargantuan task of quickly moving everyone remote while keeping IT systems alive and running for uninterrupted business operations. In the process, they accelerated not only remote operations, but the rest of the trends mentioned above.
McKinsey states:
“In just a few months’ time, the COVID-19 crisis has brought about years of change in the way companies in all sectors and regions do business…the share of digital or digitally enabled products in their portfolios has accelerated by a shocking seven years.”
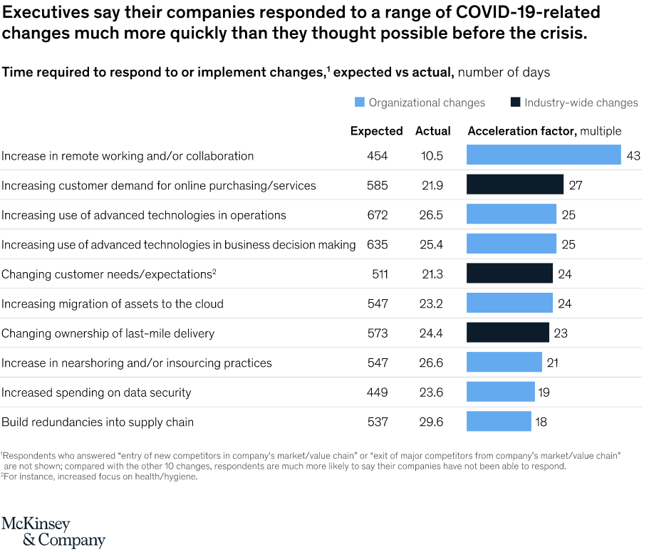
If you are seeing the data above for the first time, you could be forgiven for wondering if you’re interpreting it correctly. But you’re not mistaken: customers McKinsey surveyed reported that transformation projects expected to take well over a year to complete were actually accomplished in less than a month.
While this is good news in many ways, it also poses growing challenges for IT operations teams: when you are moving that quickly, the risk of breakage increases as well.
The growing challenges of moving fast
The challenges of innovating and modernizing infrastructure and applications, often exacerbated by the necessity of speed, can be generally divided into three main areas:
Tooling and visibility issues
Missing monitoring tools, the wrong monitoring tools, or often too many monitoring tools can lead to the same problem: gaps in visibility. Teams are disoriented by too many sources of conflicting information. They are either missing critical events because of the lack of alerting capabilities, or they are bombarded with overwhelming alert noise.
Poor diagnostic capabilities and slower remediation
When teams are presented with competing, concurrent streams of data, they often end up with many false positives. This leads to IT Ops falling back to outdated processes for resolving issues, and this in turn leads to multiple teams involved in different applications or services participating in long and ineffective bridge calls or debugging sessions. This inefficient exchange of information across many stakeholders can end up wasting resources and increasing costs.
Manual workflows
All of the above leads to IT Ops teams not having time to adopt automation, as they are busy trying to put out fires. Teams and tooling often end up disassociated and siloed – leading them to continue to rely on manual processes.
The price of moving fast and breaking
Basically – IT Ops teams are stuck in reactive firefighting:
- Despite investing in world-class monitoring tools, they’re still experiencing long outages, incidents, and performance problems, which they are trying to solve in a myriad of individual consoles.
- High-value experts are being pulled into fire-fighting and bridge calls from hell.
- No easy answers to the “What changed?” and “What’s impacted?” questions, even for those experts.

So how do you move fast, get the full value of your existing tooling investments, and avoid performance issues and outages?
Taking the risk out of innovation
- First – put your observability in order. Ensure that you have observability tools that provide full visibility across your organization (to developers, operations teams, security, and even business executives) by monitoring everything, from your infrastructure and network to your applications and services, all the way to your end-users. Make sure your tools can connect your metrics, traces, and logs, so you can see what is happening in your infrastructure and understand the context. The ability to view metrics from your infrastructure, applications, and users and correlate them to traces and logs is essential. And if possible, add in anomaly and outlier detection for intelligent alerting.
- Then – add an event correlation and automation layer on top. Correlate the alerts your observability tools create into a drastically reduced number of high-level, insight-rich incidents by using Machine Learning and AI. Add context to these incidents by ingesting and understanding topology sources as well. Then use ML and AI to determine the root cause of these incidents, including correlating them with data streams from your change tools: CI/CD, orchestration, change management and auditing – to identify whether any changes that were done in your environment are causing these incidents.
- Finally – automate as many manual processes you can. Seek out manual aspects of your incident management lifecycle and automate them, in order to free your IT Ops team from time-consuming tasks. By integrating with collaboration tools – you can also streamline the way your IT Ops teams work, allowing them to focus on modernizing and innovating the business.
I invite you to watch our webinar – ‘Taking the risk out of innovation: How to move fast without breaking‘ – to deep dive and learn more.




