



IT RCA tool
Find IT incident root cause faster with advanced AI
BigPanda Root Cause Analysis automatically identifies incident origin, explains impact, and reduces MTTR by up to 50%.
Rapidly identify and explain incident‑causing changes with an IT RCA tool
Correlate multisource alerts with change data so NOC or ITSM teams can identify and roll back specific actions and changes that cause incidents.
Automatically reveal root cause
Quickly identify the factors that cause IT incidents across complex IT environments. Accelerate root cause identification and triage. Automatically suggest remediation actions in real time.


Instantly reveal relevant change data
Root Cause Changes identifies the probable changes that resulted in an incident and reveals their context. Responders get natural-language explanations of the reasoning and statistical confidence behind the matches.
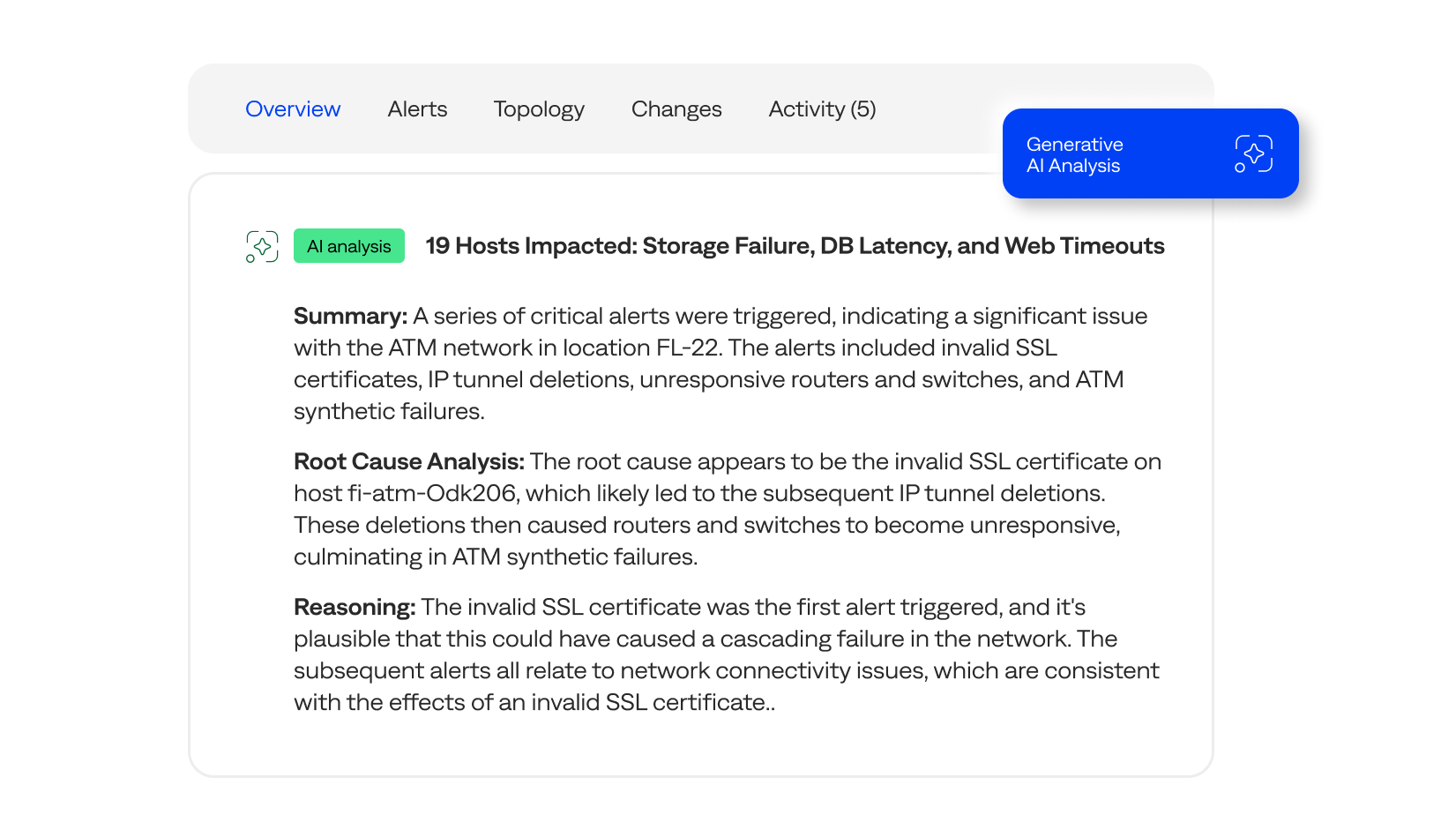
Confidently identify and explain impact
BigPanda Generative AI gives responders easy-to-understand summaries of the full impact of IT incidents across complex, hybrid-cloud infrastructures.

Access detailed analytics reports
BigPanda Unified Analytics helps measure, improve, and operationalize root cause analysis and investigation across all applications and services. Understand where and how to improve root-cause detection and incident-response workflows.
Automated IT Root Cause Analysis for ITOps
![]()
“Through the Integration Hub, BigPanda exposed [our] experts and their knowledge in the platform, allowing us to identify the root cause of an incident and reduce the overall time.”
![]()
“BigPanda Root Cause Changes gives us a clearer understanding of the underlying causes behind incidents so we can respond more effectively.”
![]()
“BigPanda helps us detect incidents and uncover probable root cause in real time, which has significantly reduced our MTTR by 78%, from 25 hours to 5.5 hours per incident.”
Agentic ITOps Platform
From firefighting to prevention: transform IT incident management with agentic IT operations

FAQ
What is IT root cause analysis (RCA)?
Why use BigPanda IT Root Cause Analysis?
ITOps teams traditionally perform root-cause analysis after an outage to identify how to prevent similar future outages. BigPanda uses AI and ML to accelerate root-cause analysis and fix problems at the source in real time, significantly reducing mean time to resolution (MTTR).
What is BigPanda Root Cause Changes?
BigPanda Root Cause Changes is an IT RCA tool that uses operations-centric AI to accurately and automatically identify change data associated with an incident. Responders gain fast, precise root-cause identification at the time of the incident to instantly uncover crucial details for resolution and reduce MTTR by up to 50%.
How does BigPanda Root Cause Changes work?
BigPanda Root Cause Changes uses AI and Open Box Machine Learning to identify patterns and correlate real-time change data with incidents. BigPanda uses 29 unique vector dimensions to identify high-confidence alerts and change-data matches associated with incident creation. Responders gain a comprehensive view of statistically relevant suspected changes.
Check out more related content



White Paper
Derisking IT Change Management with Agentic AI
Prevent incidents and reduce downtime through automated change risk mitigation.

- PlatformPlatform
- Agentic IT Operations
- Platform Overview
- AI Incident Prevention
- AI Detection & Response
- L1 Agent
- AI Incident Assistant
- IT Knowledge Graph
- BigPanda AIOps
- BigPanda Core
- Advanced Insight
- Biggy AI
- Rebranding Matrix
- Integrations
- Security & Compliance
- Features
- Detection
- Open Integration Hub
- AI Detection
- Diagnosis
- Service Desk Correlation
- Suggested Actions
- Incident Correlation
- Triage
- Automated Incident Triage
- Root Cause Analysis
- Similar Incidents
- Prevention
- Change Risk Management
- Problem Management
- Solutions
- Automating L1 Detection & Response
- Empowering Experts with AI Assistance
- Predicting & Preventing Disruptions
- Personas
- IT operations
- Incident management
- IT service management
- Site Reliability Engineering
- Industries
- Financial services
- Manufacturing
- Insurance
- Media and entertainment
- Managed services
- Airlines
- All industries