
How the right AIOps tools help IT evolve and survive change
Date: April 23, 2020
Category: AIOps Tools & Tech
Author: Aviv Shukron
Darwin was right: Change will separate the strong from the weak
“It is not the strongest or the most intelligent who will survive, but those who can best manage change” said Charles Darwin over 150 years ago – and probably every IT Ops engineer out there these days would agree with him. According to Gartner (and probably your experience as well), over 80% of service disruptions these days are caused by changes in infrastructure and software. And while change is inevitable and a prerequisite for progress and the way that we work today, we still find it difficult to manage the impact of these changes on our business using our current tools, especially when working remotely.
IT changes can generally be divided into four types:
- Planned infrastructure and software changes, which are sometimes managed by change management tools and processes.
- Continuous delivery pipelines, where often dozens of daily code deployments introduce changes into our IT environment.
- Autonomous changes, such as elastic scaling in the cloud or container orchestration.
- Ad-hoc changes, sometimes referred to as “shadow changes”, where changes in the environment are made “outside of protocol” due to human error or disregard for process.
Change management tools and processes offer some means of tracking the first type of change mentioned above. However, these are mostly separate from our IT event management tools, making it very difficult to correlate IT incidents to the changes that caused them. The other types of changes in our list (which are often the majority), are usually not well documented nor aggregated or presented in one place, and the tribal knowledge related to dealing with these changes is also spread across the organization. This makes it very difficult not only to understand the role of a certain change in creating a certain incident, but also to be aware that a change has even happened to begin with.
Evolving and surviving change
Following on from Darwin’s smart observations, if we want to embrace changes which enable progress and rapid movement, we should adapt in the way we work with them in order to minimize their impact on our business continuity.
- Automatically document changes – “If it’s not written down it didn’t happen” (at least until it wreaks havoc…). Automating change record generation should be a part of the normal development cycle. When deploying new software or scripting infrastructure changes, best practice is to inject the change records into the relevant change management systems as part of our code. Relying on engineers to manually document changes and make them available to the organization is a futile exercise.
- Aggregate and display changes – If we are documenting changes in dozens of different tools and/ or spreadsheets, and then need to manually sift through an endless amount of data to try to make sense of them, we’re obviously doing something wrong. A key part of dealing with change is having the ability to aggregate all the change records from all our tools and (at a minimum) to display them in one, easily-accessible screen.
- Correlate changes to incidents – So we’ve logged our changes, then collected them and made them accessible from one screen. Now, we need to present them in the context of our IT incidents, so that we can try to determine which of them, if any, contributed to the service disruption. Using relevant information from our organization, we can filter the changes and correlate them to our incidents based on time, domain, topology, geography and more. Implementing Machine Learning and AI can help to automatically identify the changes we suspect to be the culprits.
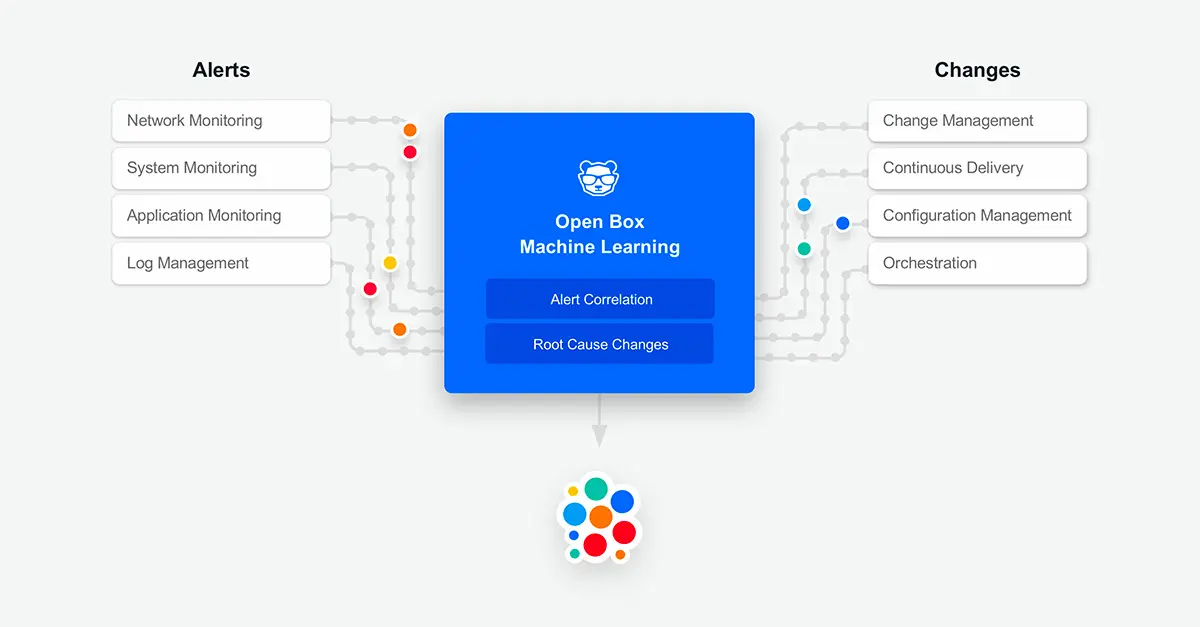
A real-life example: BigPanda Root Cause Changes
We’ve implemented many of these practices into one of BigPanda’s key features – Root Cause Changes. Using our Open Integration Hub, we aggregate change data from all change feeds and tools, including CI/CD, Change Management and Auditing. We then use Open Box Machine Learning technology to identify the changes that likely caused the incident.
By using the Root Cause Changes feature, IT Ops, NOC and DevOps teams can quickly identify changes that have caused service disruptions from within the operations console and in the context of the incident they are working on. All the contextual enrichment data related to the incident and the change are also available at their fingertips. Take a look at the following video to see how this is done.
Changes are constant in today’s fast-moving IT. In order to succeed, we need to adapt and embrace them. BigPanda can help.




