




There is no future for IT Operations without AIOps
Date: July 26, 2021
Category: AIOps Tools & Tech
Author: BigPanda
Following the release of Gartner’s Market Guide for AIOps, we had the pleasure of participating in a webinar with one of its authors, Padraig Byrne, Sr. Research Director and Analyst at Gartner. Joined by Elik Eizenberg, our CTO and Co-founder, they discussed his and Gartner’s views on AIOps.
Padraig’s main point of view, and Gartner’s key take-away – which is also echoed in the title of this post – is that there is no future for IT Operations without AIOps. Why? Because IT alert and event data is dramatically changing the IT operations landscape.
First and foremost, its overwhelming volume. Talking about the beginning of his IT career back in the 2000s, Padraig mentioned that, even back then, daily event data volumes were measured in the hundreds of millions, and how teams had to write manual rule-based processes to help them deal with this “abundance”. Fast-forward 20 years, and we find the challenge has been greatly exacerbated, with Uber releasing its M3 Time Series database, capable of ingesting half a billion events per second.
Alongside this astonishing increase in data volume, Padraig noted that we are also seeing a huge increase in data velocity and variety as we move off premises towards the cloud, and embrace microservices, containers and more. An abundance of vendors and data payload types that contain rapidly changing information, have made IT Operations so complex that no amount of training can give a human the skills required to keep up.
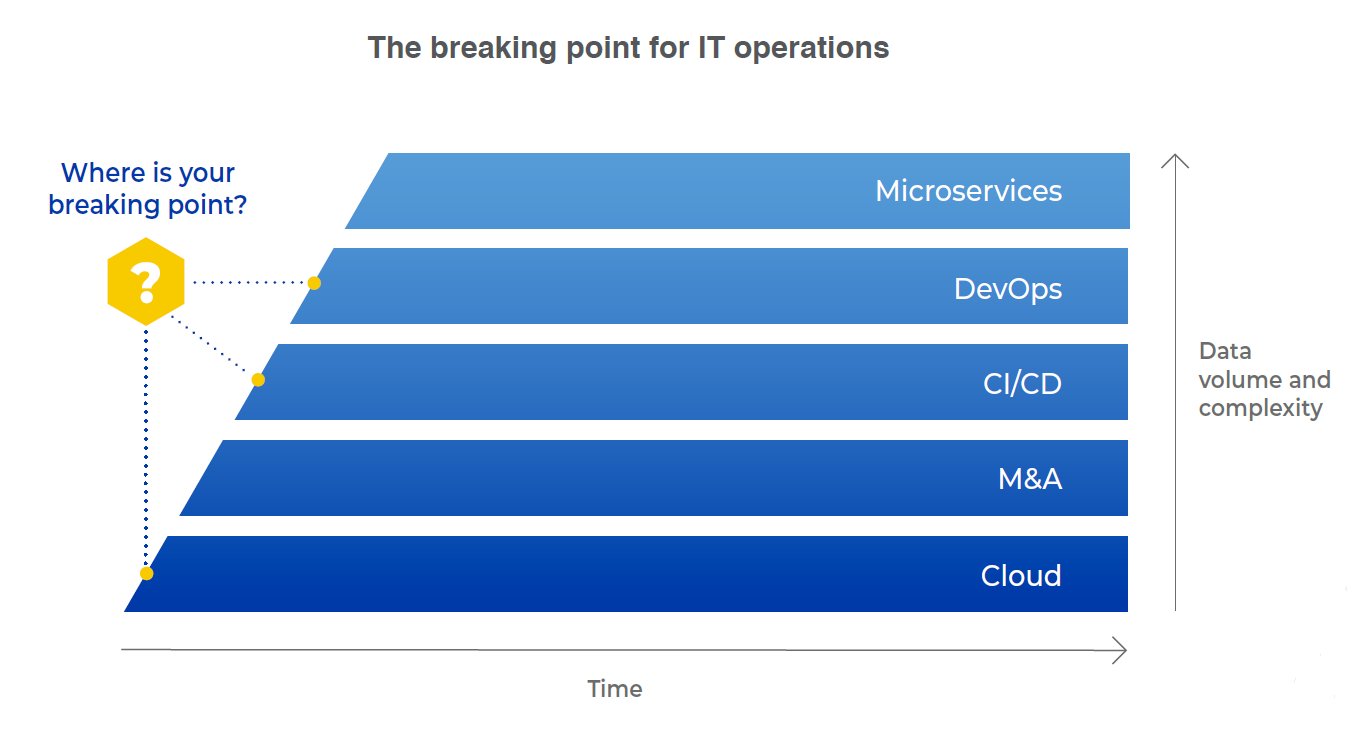
Reaching the breaking point
How did we get here? Elik and Padraig discussed five main reasons:
- Cloud migration: As enterprises migrate to the cloud, they break down their large on-prem applications, services and infrastructure into a larger number of smaller components. At the same time, they also start moving much faster. So, data velocity and volume both increase, often by more than two orders of magnitude.
- M&A consolidation: M&A activity is increasing, as companies merge and acquire others to gain immediate business advantages. When two companies come together, their IT teams are suddenly dealing with additional operational stacks and management tools, likely different from those that they are already using. They now have to manage data coming from a diverse range of tools, all speaking different ‘languages’, which again increases the complexity.
- CI/CD adoption: Code development modernization is also a huge part of today’s data explosion. Thanks to CI/CD, development teams may be pushing code to production thousands of times, and sometimes even tens of thousands of times a day. More changes mean not only more change events and data, but also more alert data from outages that could be caused by those changes.
- DevOps adoption: Developers are given autonomy to develop, run and operate applications, which encourages innovation and speeds up time to market. But, at the same time, they are free to use a wide range of tools and act autonomously, which creates a substantial operational challenge.
- Microservices: As application development continues to modernize, we see a big shift to microservices – breaking down large applications and services into many smaller ones, each of which can be scaled independently to drive higher availability. Now, if something fails somewhere in the stack, the complex dependencies between the different microservices make it difficult to analyze the incident, while also increasing the volume of event data. A single outage can manifest itself in hundreds of alerts coming from different microservices that are all tied to a single top-level issue.
Somewhere along the way, as enterprises embark on one or more of these transformations, they reach a breaking point where their legacy event management tools and methodologies are simply insufficient and ineffective!
Bridging the gap with AIOps
The only solution to this challenge is, as Gartner states, to implement AI and Machine Learning in IT Operations (aka AIOps), and letting AI/ML handle the majority of the work, providing humans with only the relevant, timely information needed to prevent and resolve outages. And this is what AIOps sets out to do.
Padraig interestingly noted that a similar approach to AI and Machine Learning has already been successfully implemented in modern aircraft. It’s called fly-by-wire, ‘the AIOps of aviation’, and it has been perfected since the late 1980s. Modern jets are complex flying machines, with thousands of electronic systems working in unison to make the miracle of flight a reality. There is no way a human pilot can physically process and properly react to the gigabytes of information generated by these increasingly complex systems. And so, computers are left to do most of the heavy lifting, giving the pilot just the right amount of data and information needed to safely fly the aircraft to its destination.
So, how do we bridge the gap between raw event data streams and the teams that depend on insights derived from those streams? Through the implementation of domain-agnostic AIOps tools.
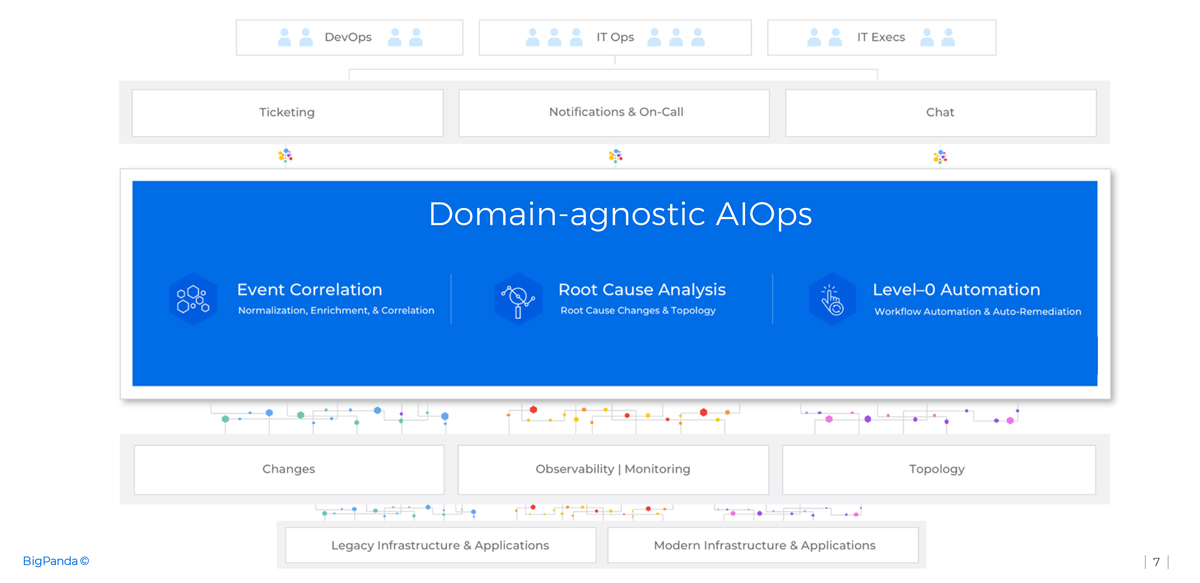
Domain-agnostic AIOps tools can ingest alert data from all observability, monitoring, topology and change tools, regardless of the vendor or whether they are running on legacy or modern infrastructure. This is a prerequisite to being able to analyze all data sources and the dependencies between them to create the ‘big picture’.
The AIOps tools then normalize these datasets into a common taxonomy, so that they can ‘speak the same language’ and be correlated, regardless of their source, and enrich these alerts with operational, topology and business context from all the sources they ingest.
The AIOps tools then use AI and Machine Learning to:
- Correlate the alerts into a lower number of high-quality, insight-rich incidents – effectively reducing IT noise by over 95%.
- Surface the probable root cause of the incident, including topology-related causes and change-related causes (Root Cause Changes).
- Trigger automatic incident management workflows, including auto-response and auto-remediation, through both internal and external tools.
These outputs are presented to human IT Ops teams through the AIOps tools’ UI, or through the UIs of integrated collaboration tools, such as a ticketing/ITSM system ,with which these teams collaborate.
A final note – Gartner suggests adopting a gradual, layered approach to AIOps implementation, cautioning us to be both patient and realistic about what we can expect from it.
We are still in the early days of AIOps, and while this area is the subject of substantial innovation, one thing is absolutely clear – there is no future for IT operations without AIOps.





