




The 3 pillars for achieving autonomy in IT Ops
Date: October 1, 2021
Category: AIOps Tools & Tech
Author: Shai Israel
Imagine a future where human IT operators and intelligent systems work together in a virtual operations room, with the systems doing the hard lifting while the humans silently supervise. Is that too much science fiction for your taste? If you strip away the special effects you are probably imagining, you will see that we are already on the way to that future with AIOps. While actual AI-augmented teams are still quite a way off, AI/ML tools are slowly but surely getting comfortable within IT Ops, NOC, DevOps and SRE teams, and leading us towards this not-too-distant future. Read how the they are doing so in this article, also published in DevOps.com.
In the last five years, the number of Internet users grew by 50 percent. In the last two years alone, more data was generated than in the entire human history up to that point. Today, five quintillion (that’s 5 followed by 18 zeros) bytes of data are produced by smart devices daily. These massive volumes of data are having a huge impact on digital operations.
Looking at the enterprise, we see similar trends: more tools generating more data and with it, greater complexity. This is a result of various triggers, including the transition to the cloud, M&A activity that introduces new tools and data into an organization, and the adoption of new technologies and methodologies such as CI/CD, microservices and more. At some point, there is so much data and everything becomes so complex, that IT Ops teams reach a breaking point where they can no longer manually manage the data being generated.
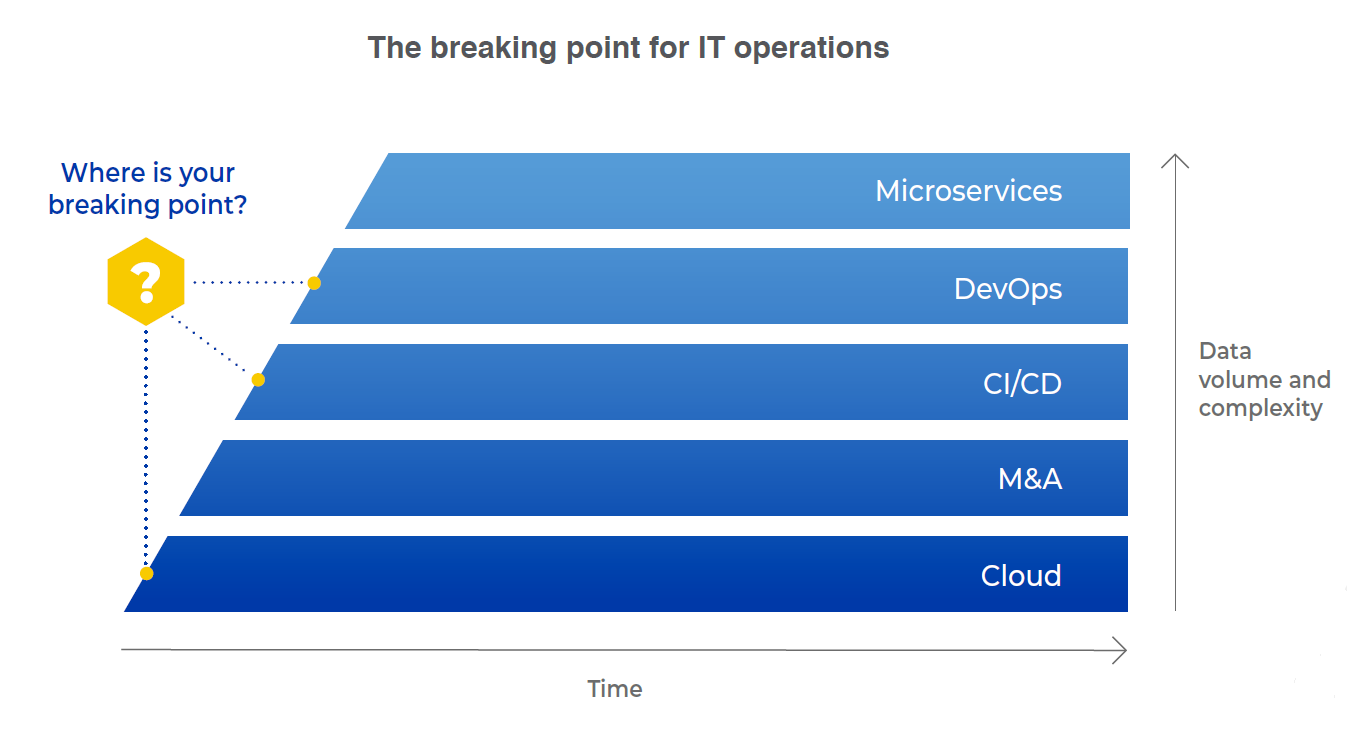
And with that, outages and service disruption become an everyday reality, with IT teams being pulled away from their strategic, business-critical projects into what is essentially firefighting.
Implementing more observability and monitoring tools simply exacerbates the problem, and scaling teams isn’t cost effective in the long term. The more forward-thinking solution is automation, and even more so – autonomy.
The road to IT Ops autonomy
Autonomy is the ability of IT Ops to operate with minimal to no human intervention. It relies on the automation of the incident management lifecycle to a degree that humans are needed only for supervision, in the same way that a single operator can supervise a modern and highly complex robotic car assembly line.
How can we hope to reach IT Ops autonomy? The following three proposed pillars can act as a guide:
- Pillar 1: Automate
- Pillar 2: Predict & Prevent
- Pillar 3: Democratize
Pillar 1: Automate
We must automate as much as possible, across every step in every aspect of incident management. It doesn’t happen overnight, but with time, and with the help of AI/ML, it is doable.
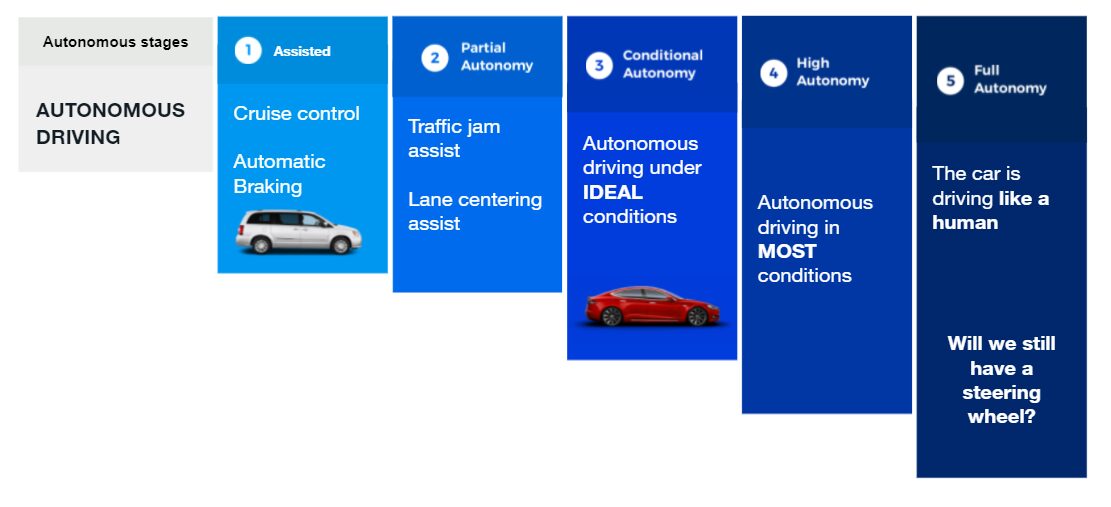
Consider the autonomous driving analogy.
Just a few years ago, cars were manual, with little to no automation. Then we moved through partial autonomy to where we are today – conditional autonomy – where the car can drive itself in ideal conditions. This is a level of automation that we are beginning to accept, some of us cautiously, others with more gusto! Meanwhile, progress continues towards high autonomy, in which vehicles will be able to drive themselves in most conditions, and one day, maybe, we’ll get to the holy grail of full autonomy, where the car will drive on its own – perhaps we won’t even need a steering wheel!
Similarly, in IT Ops, automation is a process, and it will take time to build not only the capabilities required, but also the necessary trust in AI/ML technology. Such a journey typically begins with human-driven automation, as “if-then-else” type of automations are added manually. For example, if a certain alert appears, a ticket will automatically be assigned to a specific person. As our confidence grows, the next stage could be AI-driven suggestions, whereby AI applies what it has learned from previous human actions to suggest what to automate, but the human expert decides whether to take the suggestion or not.
At some point, we will progress to allowing AI to partially automate some tasks – perhaps those that are less risky, such as collecting diagnostic information and adding it to the alert, so that the incident responder automatically receives both together. We may even automate some parts of our system, perhaps within a staging environment which isn’t production critical, and as such is a good place to validate that the automation is working as expected. Over time, as our AI and ML capabilities develop and our trust in them grows, we may eventually reach full AI-driven automation, with no human involvement at all – the AI will simply detect the fault and resolve it.
Pillar 2: Predict & Prevent
Typically, when assigned an incident, a responder will take note of the incident’s priority. But they will also rely on their common sense and past experience in deciding how to respond. So, for example, if a P3 incident had recently escalated to a P1 in 30 minutes, and a similar P3 incident now appears again, our responder will probably prioritize it, even over other incidents, to avoid a similar escalation.
While this is one of the advantages of human logic, the flip side is that the IT environments in which we work are vast and complex – no human can possibly remember every potentially relevant detail. What’s more, if a different responder dealt with the earlier incident in our example, the current responder will not have the same insight. What is needed is an element of enrichment that can input leading indicators into the platform for the next operator to see and act upon to prevent an incident.
This is where AI can help.
By identifying patterns in the data haystack – linking different incidents to the same root cause, for example – AI not only generates insights that help us solve these incidents faster, but can also predict a certain outcome. This is done by anticipating a future chain of events, so that appropriate preventative action can be taken before the event occurs. For now, this preventative action may be manually taken by the operator, but at some point in the future, automation may enable the problem to be identified and fixed by the AI, with no human intervention, before it results in an outage.
Pillar 3: Democratize
The last pillar that will help us achieve full autonomy in IT Ops is democratization of AI. AIOps should not just be accessible to advanced, mature organizations with an army of data scientists working behind the scenes. Just as anyone can accomplish almost anything online these days with just a few clicks, any organization should be able to adopt AIOps and enjoy its benefits!
Democratization is about making relevant information accessible to anyone who needs it, when they need it, and in a manner that is easily applicable and actionable. AI should be accessible through simple user interfaces, with no need for coding; the benefits of machine learning should be available to people that don’t (need to) understand machine learning models.
This democratization can be achieved by making AIOps platforms simple and accessible to all – from the admin to the user. For example, an AIOps platform might automatically suggest how admins should prioritize incidents for operators, to make triage easier, and provide instructions that even a non-expert can follow. The more such features are built into AIOps platforms, the more democratized AIOps will become.
Data volumes will continue to grow exponentially in the coming years, and the only way to eventually conquer the tyranny of overwhelming data will be to reach autonomy in IT Ops.
If you’re an AIOps vendor, keep the three pillars in mind so your customers can continue to progress towards autonomy. If you’re an IT Ops leader or tooling architect, and IT Ops autonomy is part of your vision, make sure that your AIOps vendors’ platforms and tools have been architected with these pillars and their principles in mind.
How far are we from achieving autonomy? Only time will tell. But one thing is for sure – we will get there, and if Covid-19 has taught us anything it’s that we may be seeing machine-augmented teams sooner than later.




