Improve incident triage with AIOps to reduce downtime


Downtime is expensive, both to your budget and your brand reputation. As IT outage costs increase, it’s critical to identify and prioritize incidents quickly to minimize the impact on your organization.
In a recent survey of more than 400 global IT professionals, Enterprise Management Associates found that unplanned downtime costs average $14,056 per minute. That’s an increase of nearly 10% from 2022. For large enterprises, the average is almost $25,000 per minute — $1.5 million per hour of downtime.
Minimizing downtime can help you meet your SLAs and ensure service availability.
Within the incident lifecycle, triage is the critical step of sorting through alerts to identify the most pressing issues. Resolving incidents before they become outages requires efficient triage. Effective triage also allows skilled (and expensive) ITOps staff to focus their efforts on more strategic work.
Harnessing AIOps and automation can significantly simplify, enhance, and shorten incident triage.

The pain of manual triage
IT environments are hybrid, complex, and constantly changing. They require disparate teams, tools, and applications to manage them. This complexity results in vast volumes of alerts without full business context.
These factors make it difficult for first responders to triage incoming incidents. Without context such as business priorities, service impact, and routing data, ITOps can’t assess incident severity. This wastes precious time and stresses incident-management teams.
Applications and services affect customers, service availability, and revenue differently. ITOps and NOC teams must prioritize simultaneous incidents effectively. Rapid triage requires access to each incident’s business context and metrics, including:
- Business severity
- Services affected
- Appropriate response team
- Prioritization
- Organization-specific processes, IT environments, and services
Lack of easy access to this information wastes time. Searching for relevant spreadsheets, runbooks, and other sources of institutional knowledge causes delays. Teams must often calculate metrics manually to establish an incident’s potential impact.
All these activities extend the triage phase. Delays increase the potential for SLA violations, lengthy mean-time-to-resolution (MTTR), and higher costs.
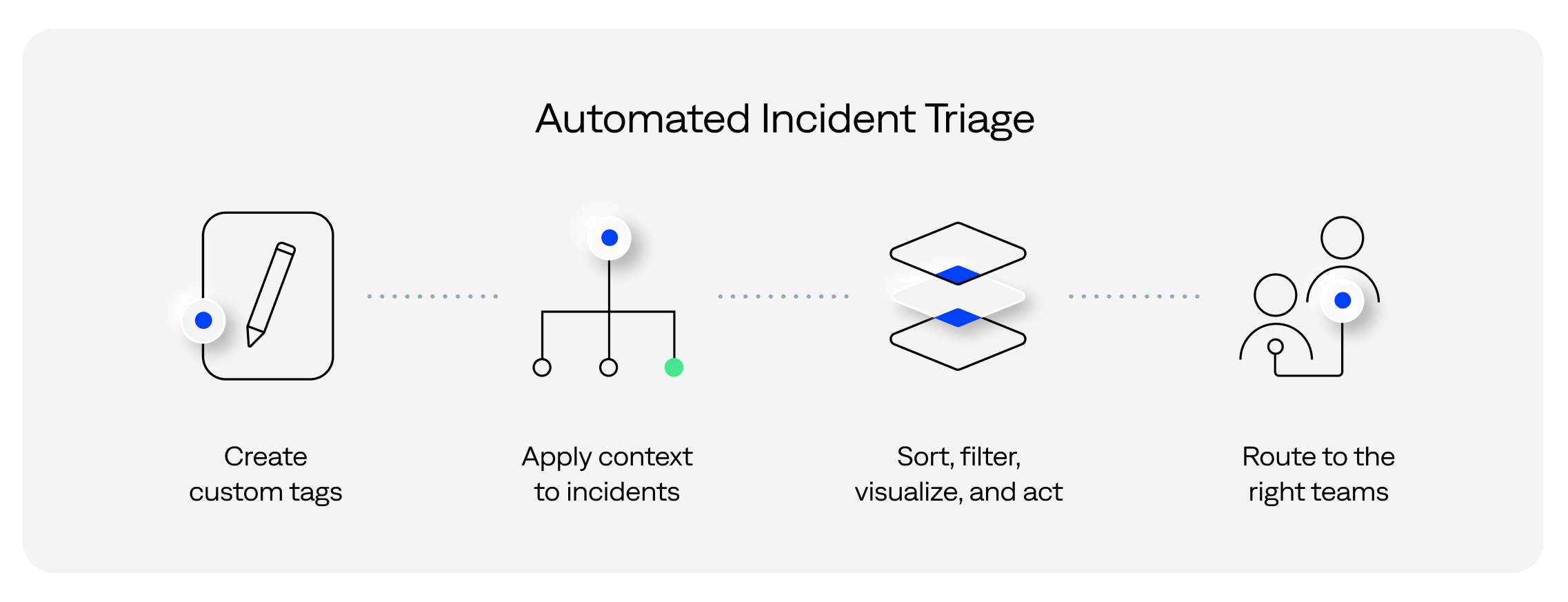
Custom tagging and automation
An antidote to this complexity is automating incident triage using a tagging strategy. For example, one that uses the following guidelines:
- Embed relevant, actionable business context. Create custom incident tags to see summary information at the incident level rather than having to review all the related alerts.
- Create formulas to calculate the tag values and metrics automatically. Remove the need for operators to do manual calculations or search for detail at the incident onset.
- Provide filtering and sorting based on tag values with visualizations of the tags. Using this detail, your teams can act on the incidents based on what they see.
- Automate routing based on tag values. Enable remediation of large numbers of incidents by relevant teams or automated processes.
Successful implementation of these processes and technologies can deliver huge benefits. Cambia Health Solutions harnessed this type of automation to achieve 83% alert compression and 20x faster incident detection.
“BigPanda has helped significantly with deduplicating, correlating, and automating our process,” said Mark Peterson, IT operations supervisor at Cambia Health Solutions. “We have a better understanding of what is impacted throughout the organization and how to fix it quickly.”
Watch our webinar to hear more from Peterson about his team’s results with BigPanda.
Automate triage to shorten MTTR
Enhancing incident triage can improve incident timelines, reducing MTTR by up to 50%.
“If we are unable to identify and understand the root cause of an incident, we are at a tremendous disadvantage,” explains Alvin Smith, vice president of global infrastructure and operations at InterContinental Hotels Group. “With BigPanda, we take advantage of machine learning, automation, and artificial intelligence to decrease the time to identify an incident. This gives us more time to resolve the incident, reducing our MTTR and keeping our services running.”
Reducing MTTR is a clear benefit, but there are more advantages to automating triage. Specifically, automation can help you:
- Increase NOC productivity: Automating triage simplifies a big part of the incident lifecycle. Less complexity improves collaboration, lowering both stress and effort for IT teams. Over time, teams can leverage the collected information to improve tools and processes.
- Improve time utilization: Reclaimed FTE hours are often a hidden cost-reducer and revenue-generator. Automating thousands of hours of manual work gives teams more time to improve and develop new services. Not only do you reduce costs but you accelerate the business.
Next steps
BigPanda can simplify triage and enrich incidents with actionable context. By combining event data with components like Generative AI and Root Cause Changes, organizations can significantly reduce MTTR.
Download “Three ways to simplify root-cause discovery” e-book to learn more about reducing MTTR.