




Build a boat, not a house: how incident intelligence and automation strengthens your observability strategy
Date: March 9, 2023
Category: AIOps Tools & Tech
Author: BigPanda
Are you a modernizing enterprise IT shop? If so, which of these statements best describes your observability situation?
- We’re evolving or rebuilding our monitoring/observability stack, but it currently has gaps. We need to find the right tools to plug those visibility holes.
- Our monitoring/observability stack is complicated and messy. We’ve accumulated tools and technical debt, and we have some visibility redundancies and gaps we need to figure out.
If either of these statements describes your reality, you’re far from alone—we’ve talked to hundreds of companies in similar circumstances. In both cases, there may be strong inclination to “get our monitoring house in order” before optimizing things farther along the IT service management chain … things like event correlation, ticketing, or automations to shorten the incident lifecycle.
It sounds reasonable, right? If the monitoring and observability layer is the foundation of your incident management tech stack, and the collaboration tooling layer is the house your people live in every day, doesn’t it make sense to build a solid foundation first, before putting up the house?
Here’s the thing, though. You’re not building a house. You’re building a boat.
Why? Because the infrastructure on which your business depends is constantly moving and changing, like the sea.
Unfortunately, since the conditions underneath you can change at a moment’s notice, your boat (and the people within it) has to be ready for anything. Those dynamic conditions could be coming from changes to monitored services, new observability tools being added, existing ones being retired, new business units or acquisitions onboarding their systems, or rapid changes in the data inundating your team.
So if you accept that your monitoring and observability approach needs to be fluid and dynamic, how do you build the best boat you can? A modern incident intelligence and automation solution, powered by AIOps, can help with that.
Building back better
Let’s consider an ITOps maturity model focused on monitoring and event processing as we revisit our original question. Did you choose option 1? If so, you’re probably somewhere around Phase 1 in this model:
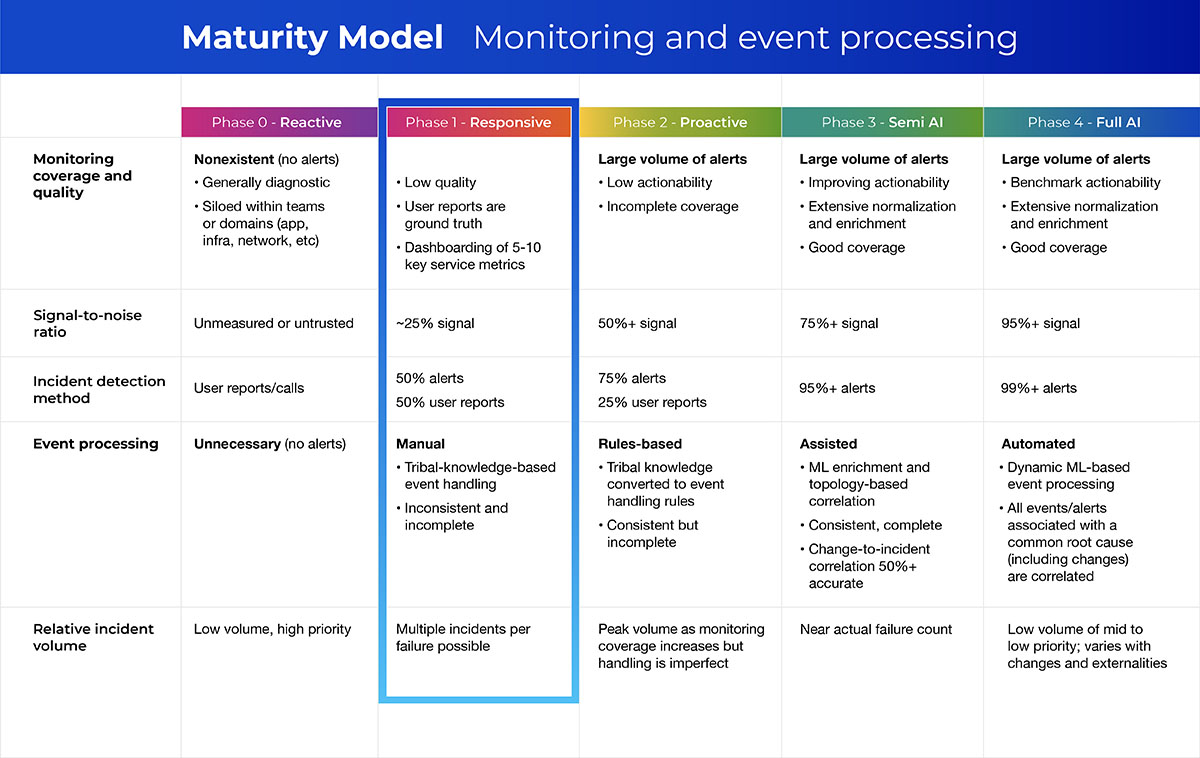
With this model, you can see where your organization’s monitoring strategy lies today and how to move your organization toward a more mature, autonomous observability posture. Organizations in Phase 1 are often working toward building out or modernizing their monitoring stack. Depending on other priorities, they may or may not be making progress. Meanwhile, visibility gaps persist that rob the team of the contextual data they need to quickly resolve incidents, further complicating their priorities.
There are other risks that go along with continuing to chase the “optimal” monitoring tool stack. Every time a new tool is evaluated or deployed, the incident data being fed to your response team changes, and the volume of incoming data goes up. This causes confusion, retraining, and capacity issues for the team. If a bad call was made and a tool needs to be pulled back or replaced (hey, it happens), the ripple effects on your team could cause further problems. And as business requirements change and new services arrive to be supported, an observability environment that was approaching stability could be thrown back into chaos.
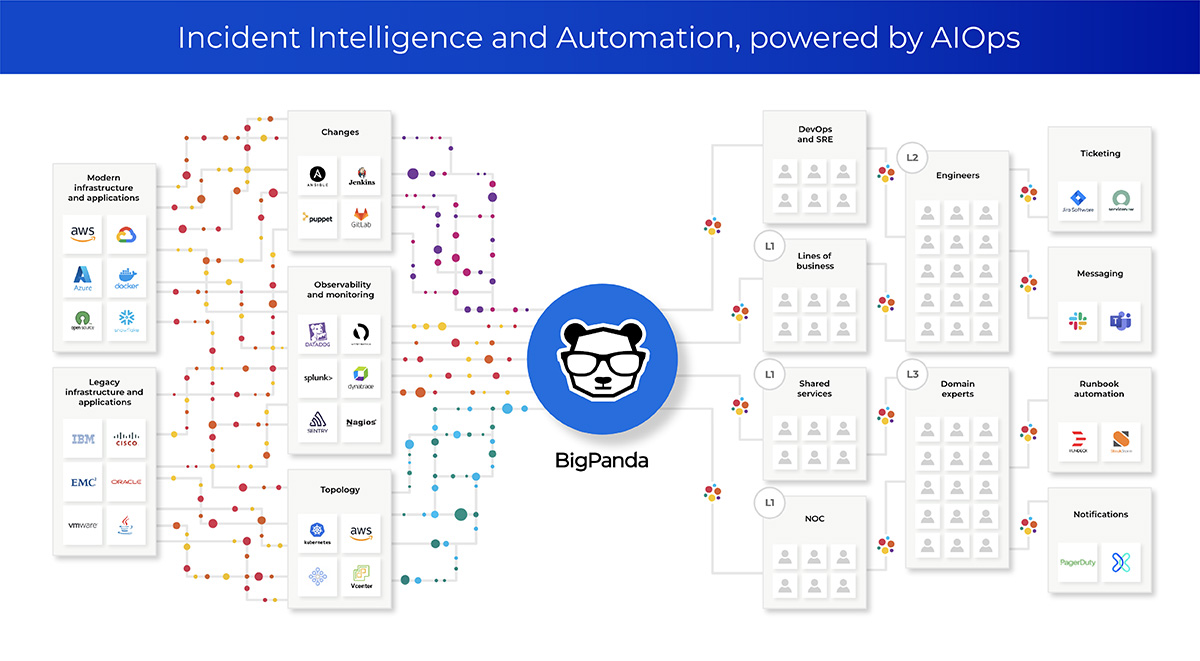
A modern, AIOps-driven incident intelligence and automation solution, dropped in between your monitoring tools and your ticketing/collaboration stack, can be immensely helpful. It will immediately eliminate noise from your observability data sources and create actionable incidents instead, dramatically improving your ITOps team’s bandwidth to handle issues as they arise.
Perhaps more importantly, a good incident intelligence and automation solution can become a foundational piece of your team’s incident management workflow, providing a stable source of truth for the alerts that actually warrant their attention.
Even if your organization standardizes around an existing system-of-record (such as a ticketing system like ServiceNow), its users will find that tickets become less frequent and the ones that are created are much more useful when incoming alerts are filtered by an AIOps event correlation layer. This is because noise is reduced, alerts are bundled together, and records can be annotated with relevant data to accelerate incident response (such as recent changes, affected services, or deduced priority levels).
This means that monitoring and observability data sources can be added, removed, or swapped out like Lego bricks, with no negative impact to how ITOps detects or manages new incidents. That goes for new services that must be supported by ITOps as well. Newly created applications and infrastructure feed data to ITOps using the very same AIOps capabilities, which correlates the new incoming alerts with the intelligence and efficiency it already provides for existing services.
The upshot of all of this is that changes to data sources, monitoring tools, or managed services effectively become frictionless events for ITOps, and a huge portion of the risk normally attached to those types of changes is eliminated. In other words, your boat becomes much more seaworthy—no matter what is happening underneath the hull.
Rationalizing tools
On the other hand, maybe your IT organization has been around the block a few times. Perhaps you have a legacy stack of services to support in addition to a modern collection of cloud-based applications to bring online. Maybe you’re inheriting new infrastructure through acquisitions that occurred above your pay grade. In any case, you chose option 2 in response to the initial question above. You likely have what could affectionately be called a bird’s nest of monitoring tools, along with all the chaotic, overlapping visibility problems that came with them.
This time, you’re probably somewhere around Phase 2 in that same maturity model:
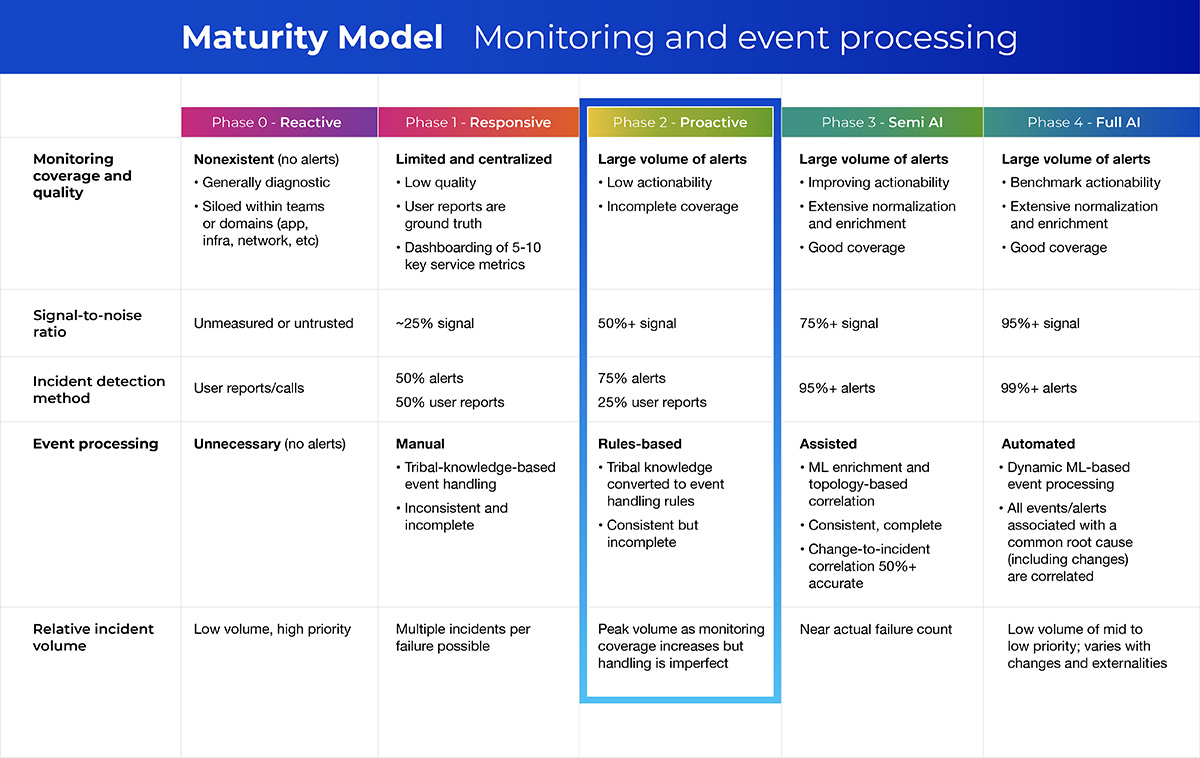
You might be tempted to clean out your bird’s nest before adding an AIOps solution upstream. After all, garbage in equals garbage out, right? Well actually, it turns out that bringing a modern AIOps-powered incident intelligence and automation solution into the mix early can still offer tangible benefits.
For starters, you’ll immediately see significant noise reduction benefits that will return bandwidth to your team almost immediately.
ITOps teams can use this newfound bandwidth to understand where the noisiest, dirtiest data sources are and correspondingly focus their efforts. They can also get insights on where their visibility gaps are and research solutions to fill them. With every optimization, the team enjoys growing alert compression, improving visibility, and more actionable incidents.
Additionally, since multitudes of alerts are rolled up into individual incidents, incident intelligence solutions can provide a unique, holistic view of your entire monitoring and incident management pipeline. If they provide the right dashboard or analytics views, your ITOps team can now easily see which monitoring tools are providing value and which ones are redundant. This can be valuable information when budget season rolls around (basically, every season) and you’re trying to reduce the amount of deadweight your boat carries around.
The need for speed
One common objection that often comes up relates to time. AIOps projects have historically received a bad rap for taking a long time (often, years) to return any value, and they have often fallen far short of the lofty goals initially set by the organization and the AIOps vendor. Knowing this, you may balk at delaying your efforts to modernize your observability stack in order to install an AIOps solution first.
Things today are very different, and the good news is that solutions with rapid time to value do exist.
You can choose a vendor that understands your ITOps use cases, has proven technology to allow go-lives in just a few weeks, and can promise attainable outcomes and prove to you that they have a solid basis for delivering them.
BigPanda has been helping option 1 and option 2 organizations—including some of the largest ones in the world—build better boats for years, with an AIOps-powered Incident Intelligence and Automation solution that supports any evolving observability strategy. Most of our deployments complete in under three months – we invite you to reach out and find out why.





