The results of our 2019 “Future of Monitoring and AIOps” survey are in


IT operations is at a crossroads. The increasing complexity of IT infrastructure and software is challenging IT teams and the business. So this year we decided to focus our survey on what IT Ops execs, managers and practitioners think about the current state of their operations, the future of their systems and the role automation and AIOps might play in their transformation.
We’re pleased to report that 1,300 IT professionals took the time to answer our survey, giving us a comprehensive and meaningful look into their IT operations and the challenges they face. The result is an insightful study examining the current status, the developing trends and the expected future of IT monitoring and AIOps.
So what did our respondents have to say?
Noisier, More Complex and Faster
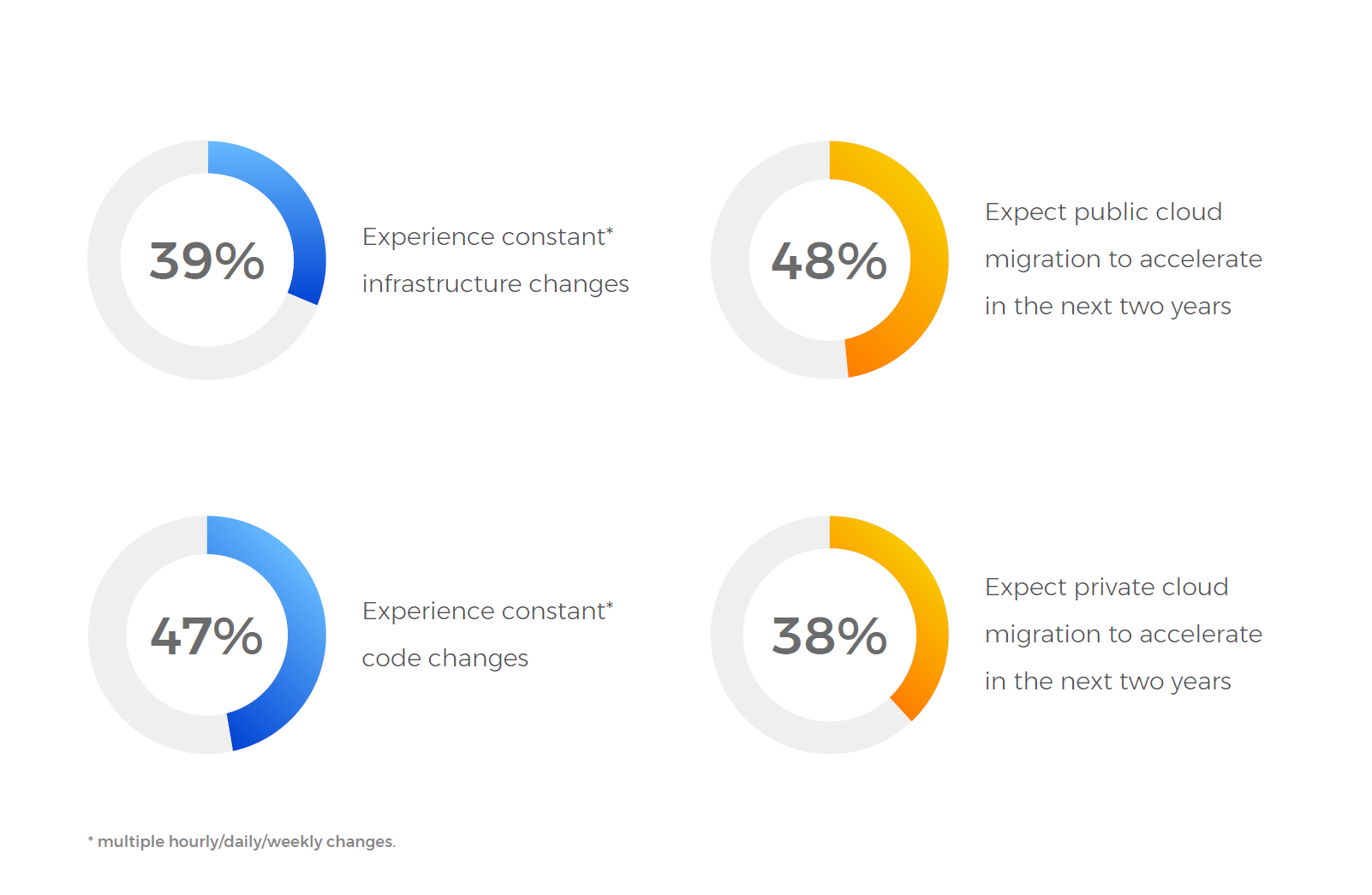
Everyone agrees that IT is becoming more noisy, complex and fast moving by the day. Nearly half of our respondents experience hourly to weekly code changes, and also expect public cloud migration to accelerate in the next two years. They are already using more than 10 different monitoring tools to contend with these changes and believe their IT Ops/NOC workloads will only increase in the next two years.
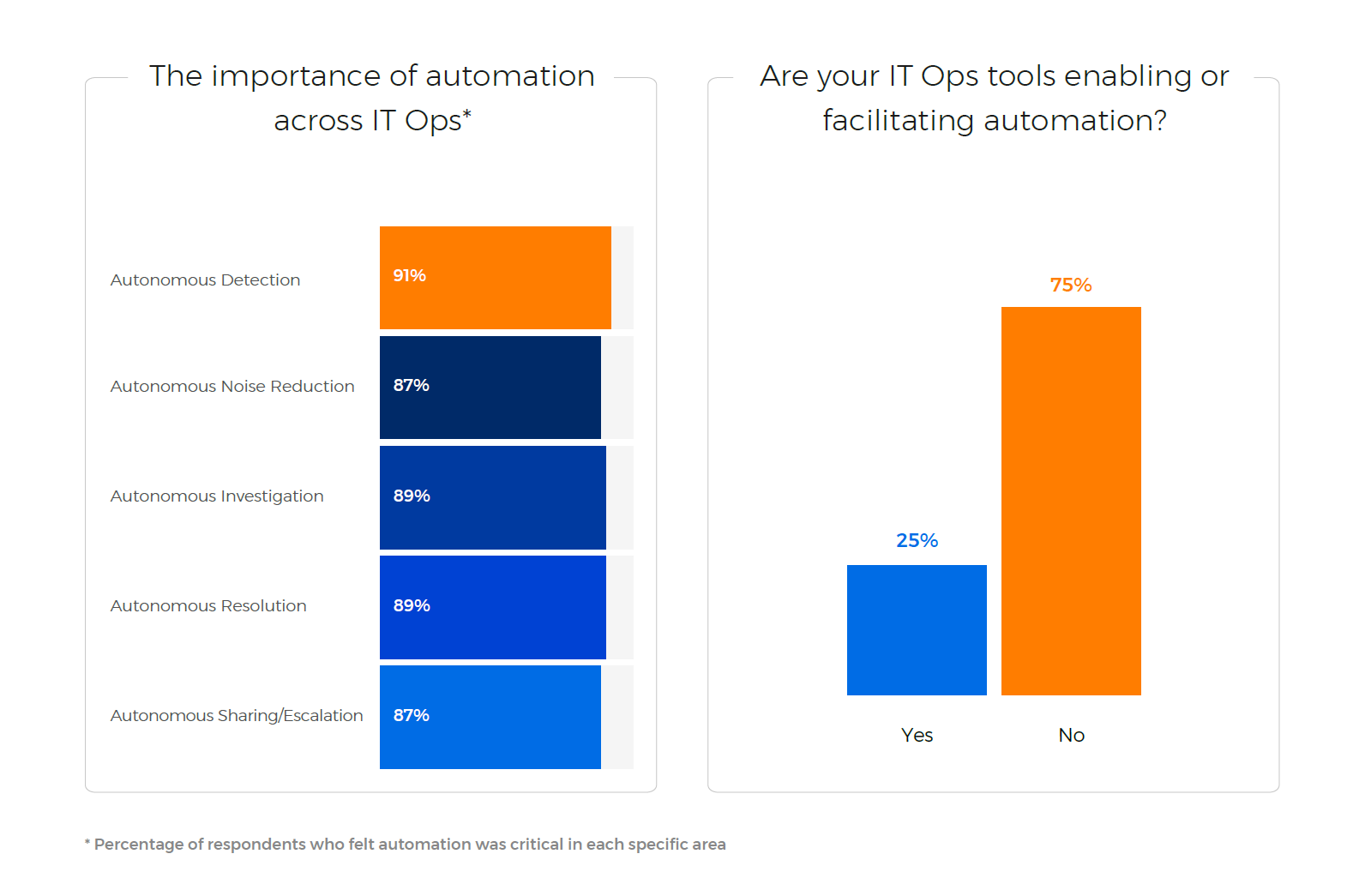
And how are they coping? Well, very few teams seem satisfied with their ability to handle the different aspects of their incident management, and three-quarters of IT teams don’t feel their IT Ops tools enable automation – which they deem essential to solving these difficulties.
Automation and AIOps to the Rescue
Most respondents feel more automation and the implementation of AI and Machine Learning (ML) in their organizations will offer them the capabilities they are looking for and nearly one-third are actively evaluating and researching AIOps tools (AI & ML enabled IT OPs tools).
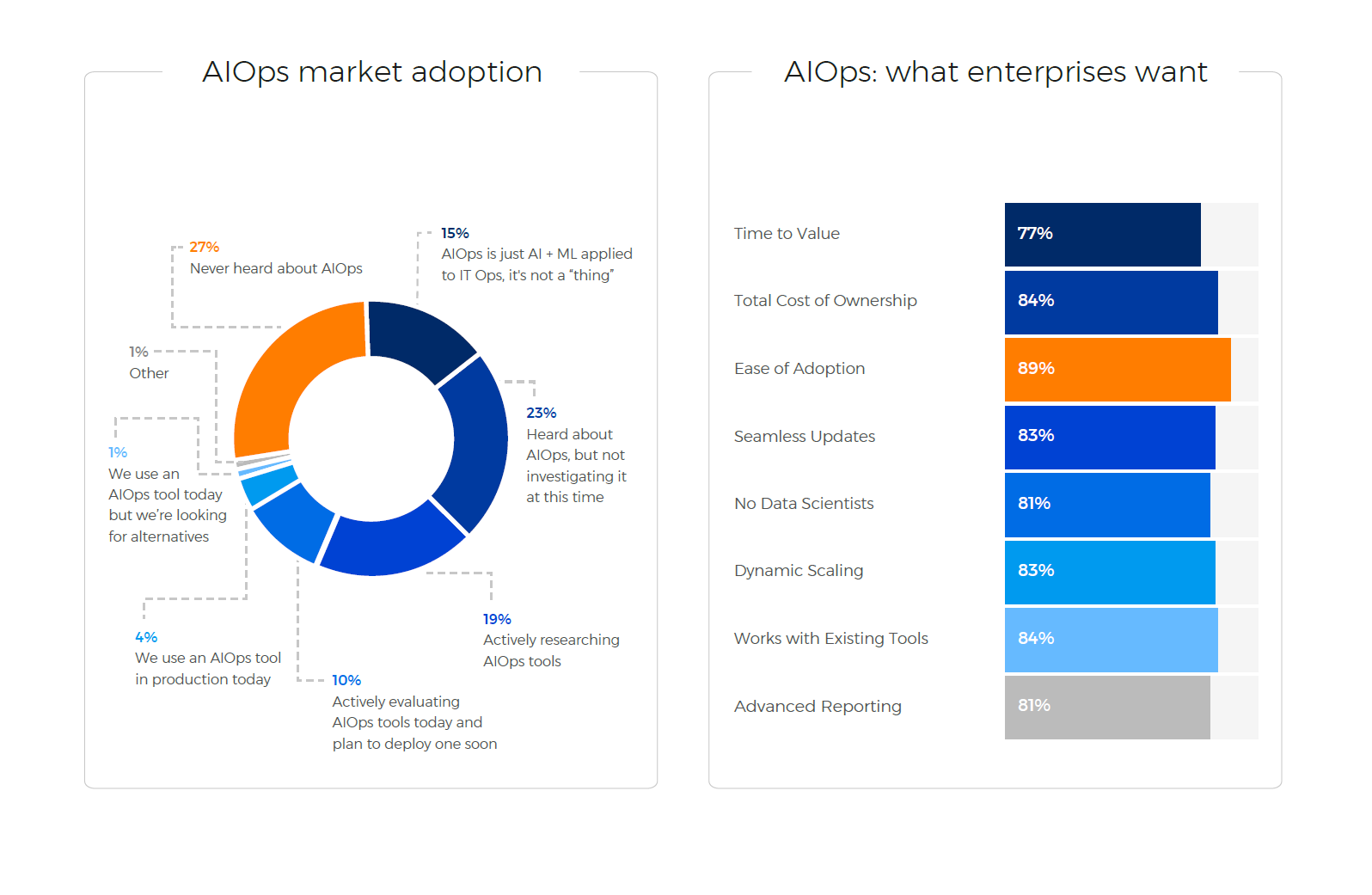
But the vast majority of respondents don’t want to rely on data scientists in order to operationalize their AIOps tools and are wary of opaque “Black Box” tools – expressing the necessity of being able to see, edit and test the ML logic before going to production.
Looking Forward
But the biggest challenge exposed in this survey within IT Ops, is the fact that most respondents see their workloads increasing in the future… yet their budgets are expected to stay flat or even decrease. And what is their suggested solution for this impossible situation? Well, you’ll have to read the survey report to find out…
To see the full results of the survey and discover more insights on the future of monitoring and AIOps, download the full report here.