



Incident correlation: Cross-domain visibility. Smarter triage. Faster L1 teams.


IT incidents are rarely isolated. A network disruption can trigger degradations in infrastructure, which can ripple and cause application errors and end up causing a flood of user complaints. When an L1 operator looks at a single incident, they see only part of the story. Outside their immediate scope, other incidents are actively occurring that are either directly related or impacted by the same underlying cause. Without broader visibility, there is no way to know.
Operators are left to manually search for context and stitch a cohesive story together. They often re-read tickets across multiple domains, look across different observability dashboards, and try to determine whether incidents are unique to their own domain or a symptom of a larger environmental issue. All of this has to be accomplished in under a 15-minute SLA.
How different would your operations look if every L1 operator opened an incident already knowing the full blast radius, before triage even begins?
Now they can. Incident correlation is now available in BigPanda, providing L1 teams with crucial cross-domain visibility to better assess incident impact and triage more accurately.
Cross-domain incident correlation transforms our operations from reactive noise handling into proactive service assurance by allowing us to pull in related incidents across our network. By giving L1 teams a single, contextualised view of incidents across network, cloud, and platform, we significantly reduce triage time, accelerate resolution, and minimise customer impact. The result is faster MTTR, lower operational cost, and a step-change in service reliability at scale.
-Dan Bartram, Head of Platform Engineering & Automation, Gamma Communications
The problem with triaging incidents in isolation
These challenges are not unique to one type of organization. We hear the same pain points from L1 and SRE teams across industries:

Rule-based correlation is broken,
Rule-based correlation is only effective in stable, predictable environments where you can anticipate every incident coming your way. In reality, that’s rarely the case. Modern environments generate incidents that are multi-dimensional and unpredictable, requiring reasoning that goes well beyond what rules provide.

Incidents are siloed; the root causes aren’t,
Teams know that incidents that happen in their domain aren’t always siloed. Service degradation in one area is frequently linked to incidents happening in another domain. But there’s no way to see the causal chain and the impact it has on the entire organization.

Triage is manual, and SLAs don’t wait,
With a shrinking window to respond, operators don’t have time to manually determine which incidents are related. Without that context, triage becomes a guessing game.; Teams are making decisions without a clear picture of impact, scope, or priority. The result is incomplete assessments, misrouted escalations, and preventable SLA breaches.
Alert correlation vs. incident correlation: What’s the difference?
Alert correlation is the process of grouping noisy monitoring events into actionable incidents. It’s scoped to a single domain, rules-based, and primarily designed to reduce alert noise.
Incident correlation operates at a fundamentally different level. Rather than grouping alerts into incidents, it utilizes AI to infer and identify relationships between incidents that already exist across domains, teams, and shared infrastructure. Where alert correlation asks “what alerts belong together?”, incident correlation asks “which of my active incidents are actually the same problem?”
Previously, it was impossible for L1 teams to see how a network incident was related to an infrastructure incident that was driving an application failure. Incident correlation closes that gap without any predefined rules, and without disrupting the alert correlation that’s already working.
Introducing incident correlation from BigPanda
BigPanda incident correlation uses AI to automatically cluster related incidents so your team can stop chasing symptoms and start solving the actual problems.
Incident correlation draws on a broad range of contextual data, including natural language, topology data, CMDB relationships, and historical runbooks to uncover dependency-driven connections that rule-based systems consistently miss. The result is a comprehensive view of your incident landscape, delivered automatically the moment an incident occurs.
How incident correlation works
When an incident is detected, incident correlation immediately begins analyzing the full landscape of active incidents and their relationships. Here’s what your team sees:

The cluster overview gives operators a high-level understanding of how many incidents are related to one another, as well as the total number of relationships.
Cluster overview: A summary of the primary incident and all related incidents grouped into a correlation cluster, with a count of total relationships and an AI-generated explanation of what is happening across the cluster.
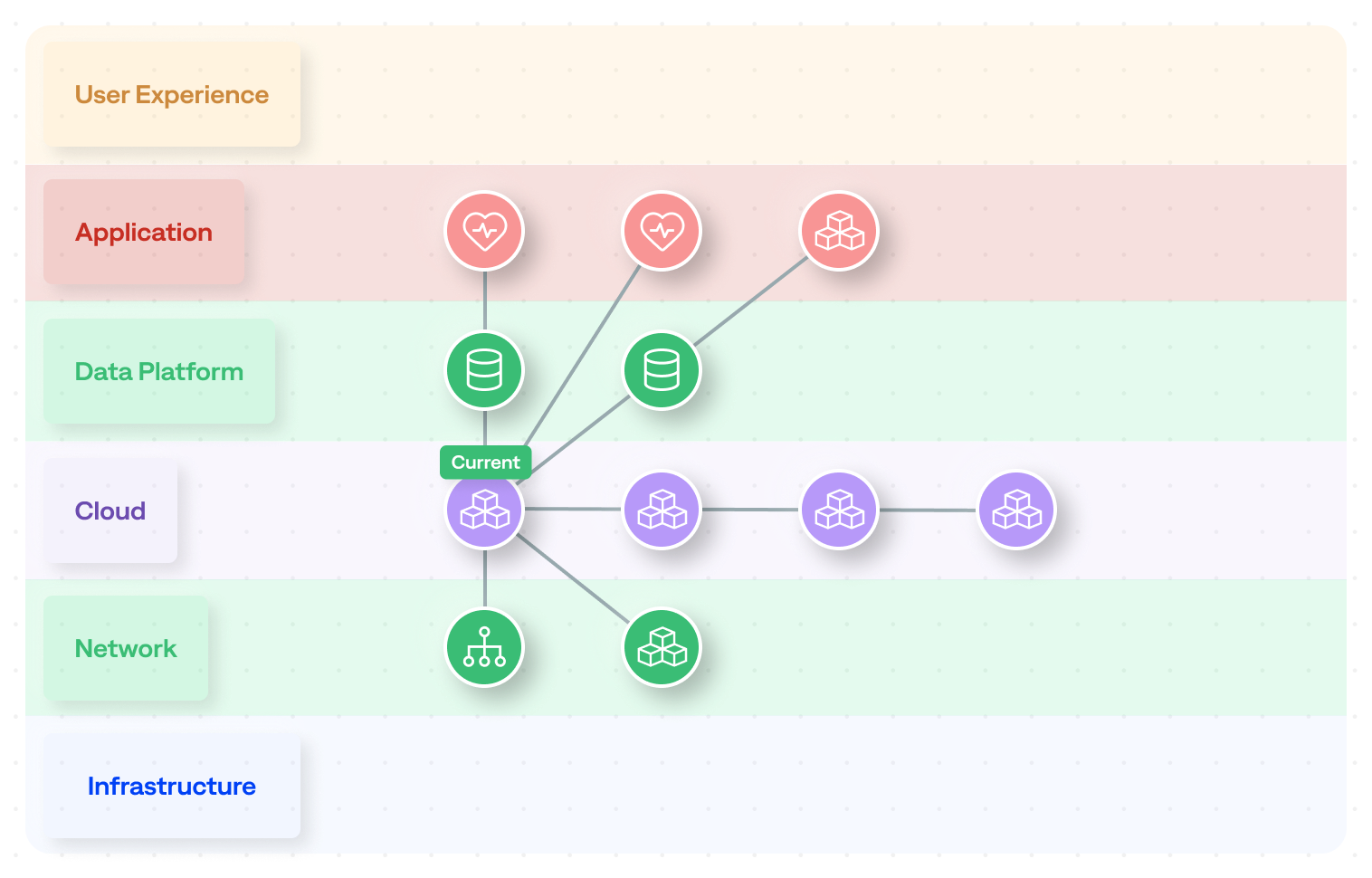
Relationship visualization: Interactive views of how incidents relate to each other, with multiple layout options, hierarchical, circular, and layered, for a clear visual picture of dependencies and propagation paths. The visualization points directly to the suggested root cause incident.

AI summaries: Context is surfaced automatically using natural language. Responders get an immediate understanding of what’s happening, what’s related, and where to focus, without having to interpret raw topology data or run manual correlation queries.
From noise reduction to cross-domain visibility
Alert correlation changed how enterprises handle overwhelming alert noise. Incident correlation takes it to a new level by giving every L1 operator the visibility and context to triage like a tenured SME or experienced SRE.
Tenured SMEs and SREs have a deep understanding of how their IT environment is architected, where incidents are likely to originate, and how incidents propagate across domains. This knowledge is usually hard-won and undocumented. Incident correlation bridges that gap by giving L1 teams cross-domain visibility and automatically surfacing how incidents relate across domains, which services are impacted, and where the priority lies. With access to this level of context, L1 operators can make more confident decisions. At a glance, they can understand whether to resolve the incident themselves or escalate immediately to exactly the right team.
When L1 teams are better equipped to handle complex, cross-domain incidents on their own, senior engineers are freed from reactive incident management and can focus on what they do best: process improvement, architectural decisions, and proactive work that actually moves their businesses forward.
Stop chasing symptoms. Find the root cause.
The cost of getting this wrong goes far beyond downtime. It’s the unnecessary escalations, the missed SLAs, the L2 and L3 hours spent re-reading tickets that should have been connected automatically, and the L1 and outsourced team costs that compound every time an incident isn’t triaged the first time accurately. Incident correlation eliminates that cost by giving every operator the cross-domain intelligence to get it right from the start.
Contact your account team to discuss setting up Incident correlation in your environment.
Ready to see it in action? Book a demo at BigPanda.io.




