



Monitoring & Observability Report Top Findings


Today, BigPanda released our first-ever research report based on data gathered from our agentic IT operations platform. Our Monitoring and Observability Tool Effectiveness for IT Event Management report provides insights and benchmarks on incident detection and noise reduction for 130 enterprise organizations, including the monitoring and observability data sources integrated with BigPanda.
IT teams must monitor increasingly complex and fragmented IT infrastructures, and the need for instrumentation that monitors those systems is simultaneously growing. Observability owners are expected to have end-to-end visibility across every layer of their applications, services, and infrastructure. The expectation is that these teams can understand performance in real time and confidently report that critical systems were monitored if a significant incident occurs.
Adding additional layers of observability causes enterprises to struggle with vast amounts of data signals hidden in overwhelming noise. However, the increase in data doesn’t directly translate to an improved ability to detect critical or emerging alerts before they become incidents. Our research reveals a troubling signal-to-noise problem: just 18% of incidents were actionable. BigPanda solves this by dramatically reducing alert noise by up to 99.9% and producing higher-quality incidents so L1 teams can quickly and accurately detect alerts and incidents to respond to.
Let’s dive into some of the key findings of the report.
Full-stack observability remains an illusion
Most enterprises adopt multiple observability and monitoring tools to gain visibility across increasingly complex IT infrastructures. The average BigPanda customer had ~20 data sources, and almost 80% had 10+.
However, these investments are still falling short of delivering the desired results. The monitoring and observability tool effectiveness matrix shows that only a few observability tools deliver strong coverage (percentage of actioned incidents) and quality (actionability rate). In addition, despite their popularity, open-source tools had a low impact at the enterprise level. This suggests that even widely used tools often generate more noise than actionable insights.
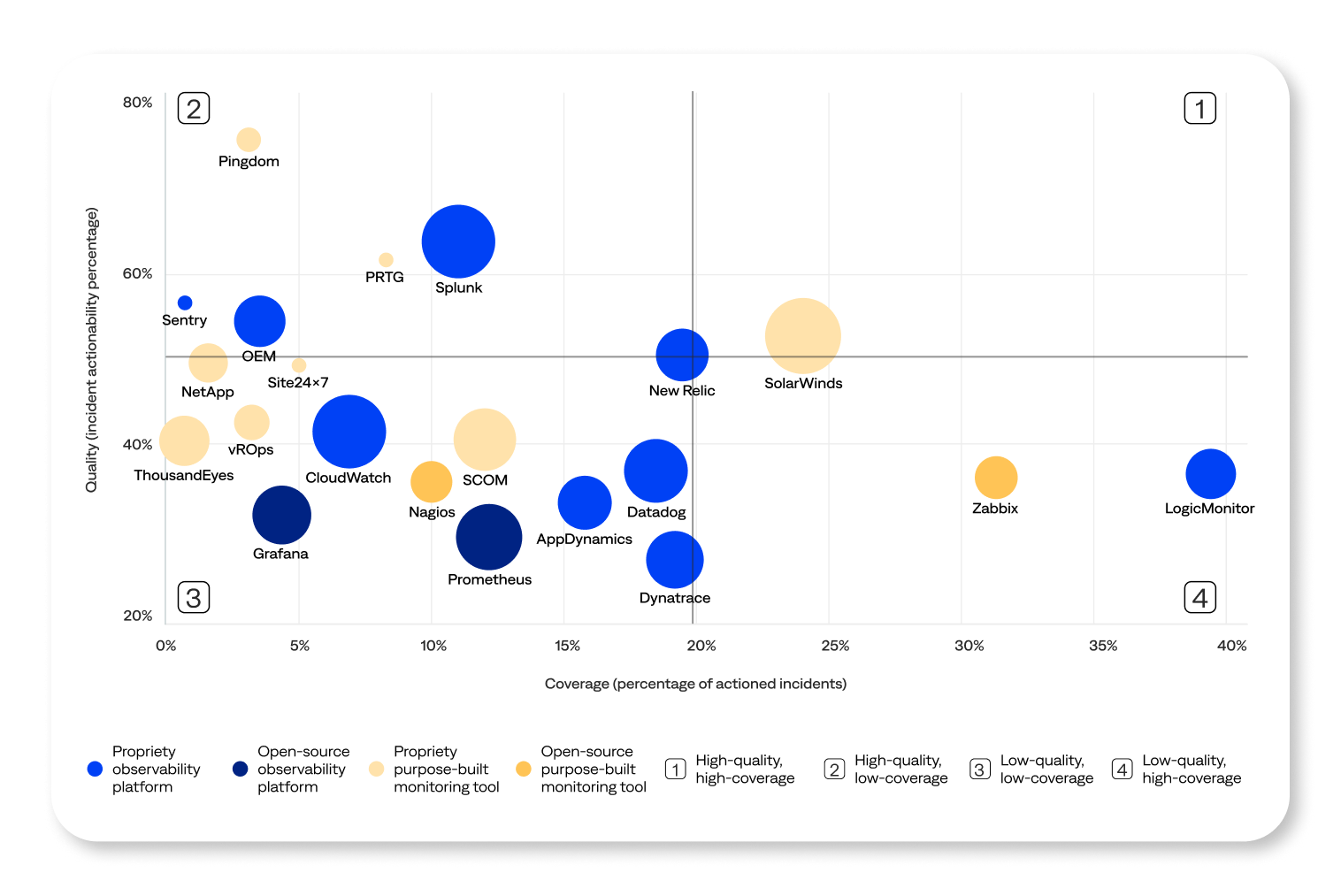
While observability and monitoring tools are crucial for understanding system health, they are insufficient for effective IT incident management. No single tool can provide comprehensive visibility across the entire technology stack. When enterprises deploy multiple monitoring and observability tools, it is difficult to centralize data and detect important alerts. Giving operators more data to sift through isn’t the answer. They need access to the correct data, presented in context, to detect and respond to incidents effectively.
More monitoring tools don’t equate to greater value
Adding more and more layers of observability has the side effect of drowning your teams in data. Our research found that monitoring and observability tools create 9.6 million events annually for the average enterprise, with 50% of organizations sending more than 10 million events a year to BigPanda. Of these events, 27% occurred on weekends, which is bad news for your on-call teams.
This data highlights the disconnect between the belief that adding more observability tools to cover applications, services, and infrastructure will lead to more effective ITOps and incident management. The sheer volume of alerts these tools produce, combined with siloed data and workflows, makes it extremely difficult to manually identify vital, actionable alerts. In fact, despite investing heavily in observability tools, more than half of the organizations included in the study had an alert actionability rate of less than 20%.
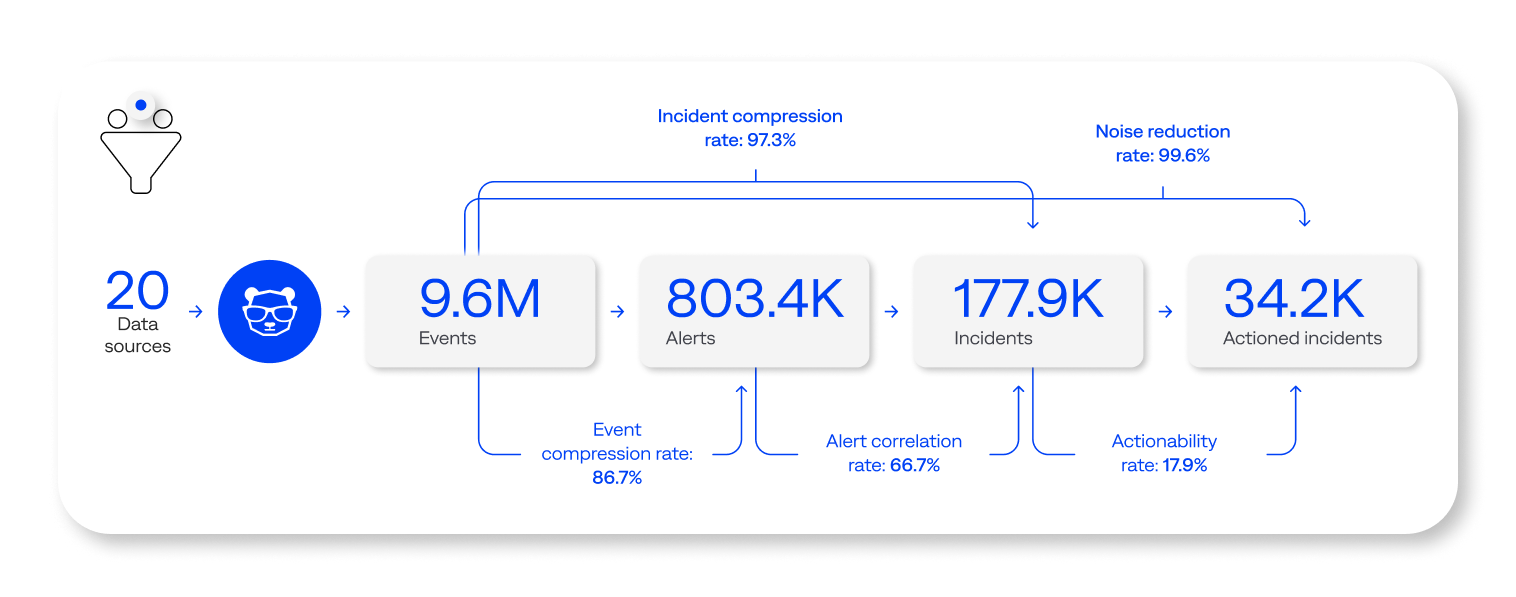
There are opportunities for tool rationalization by reducing investment in low-performing tools, consolidating around higher-impact tools, and optimizing the existing tech stack. BigPanda can help teams understand the value of alerts from each observability tool they use and tune, improve, and rationalize observability tools.
BigPanda customers experience exceptionally high alert noise reduction
Alert fatigue is a serious problem. ITOps teams often face an overwhelming volume of notifications, many of which are false positives or low-priority alerts. They have to spend significant time sifting through these alerts, which reduces team efficiency and slows response. In this noisy, chaotic environment, your teams can easily miss critical issues, leading to system failures or prolonged downtime.
BigPanda can significantly reduce alert noise. Most (82%) of the BigPanda customers included in the study achieved at least 97% noise reduction, while more than half reduced noise by 99.5–99.9%. This statistic shows the effectiveness of agentic AI-powered ITOps platforms for filtering, deduplicating, and correlating events.
Reducing alert noise ensures that your teams can focus on critical, actionable alerts. By filtering out non-essential alerts, your teams can identify critical issues faster and significantly reduce response time. Your organization benefits from reduced downtime, a more resilient IT infrastructure, and happier customers.
Enriching alerts with contextual data boosts their actionability
“Adding context to enrich alert data leads to more effective prioritization, resulting in faster problem resolution and fewer service disruptions.” — Paul Bevan, Research Director of IT Infrastructure, Bloor Research
Inconsistent alert data is a challenge for ITOps and ITSM teams. To respond to incidents efficiently, operators require the full context surrounding incidents, going beyond the basic metrics, events, logs, and traces (MELT) data that observability and monitoring tools typically capture. MELT data’s raw, specific details are helpful for forensics and triage. However, getting a complete picture of an incident and its impact requires additional information, including configuration management database (CMDB), cloud and virtualization management, service discovery, and application performance monitoring (APM) data.
Using AI to enrich alerts with this contextual data changes the game. Our research found that enriched alerts were 28% more likely to drive an actionable response by L1 operators.
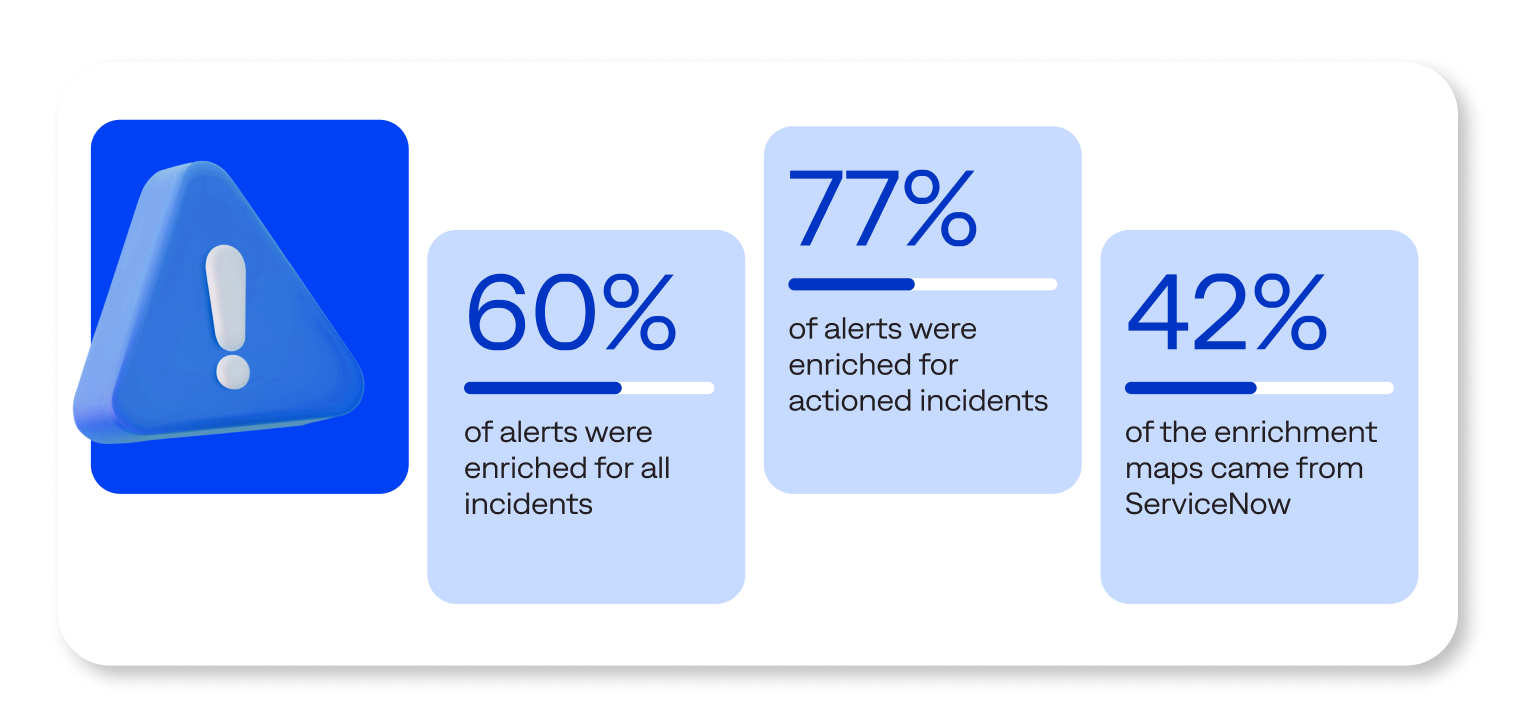
This comparison indicates that alert enrichment significantly improves alert quality and operator confidence. When alerts contain the full context surrounding an incident, operators can immediately understand the business impact of a given alert and respond appropriately, improving operational efficiency and service availability.
Healthy alert correlation is powerful
Messy data is a reality in ITOps, but that doesn’t mean you have to be satisfied with less than a comprehensive picture of your infrastructure. You can get a holistic picture by unifying existing data across your operational environment, including monitoring, topology, CMDB, and change data. When you apply AI to correlate and augment that multidimensional data, your teams can quickly uncover meaningful connections and collaborate to resolve incidents. However, while correlation is a powerful tool, 100% correlation shouldn’t be the goal.
“The goal isn’t simply to reduce ticket counts, it’s to intelligently group alerts to surface shared root cause and drive the correct response,” said Josh Sigler, a Principal Analytics Architect at BigPanda. “Over-correlation leads to bloated incidents, misrouted teams, and broken compliance processes, while under-correlation leaves you buried in noise.”
The sweet spot lies in thoughtful, cross-domain correlation that connects teams, highlights dependencies, and enables fast, targeted action. According to our research, about half (49%) of organizations fell into the healthy alert-to-incident correlation range (40–75%). Those that did showed stronger filtering, a more manageable incident volume, and a higher operational signal fidelity.
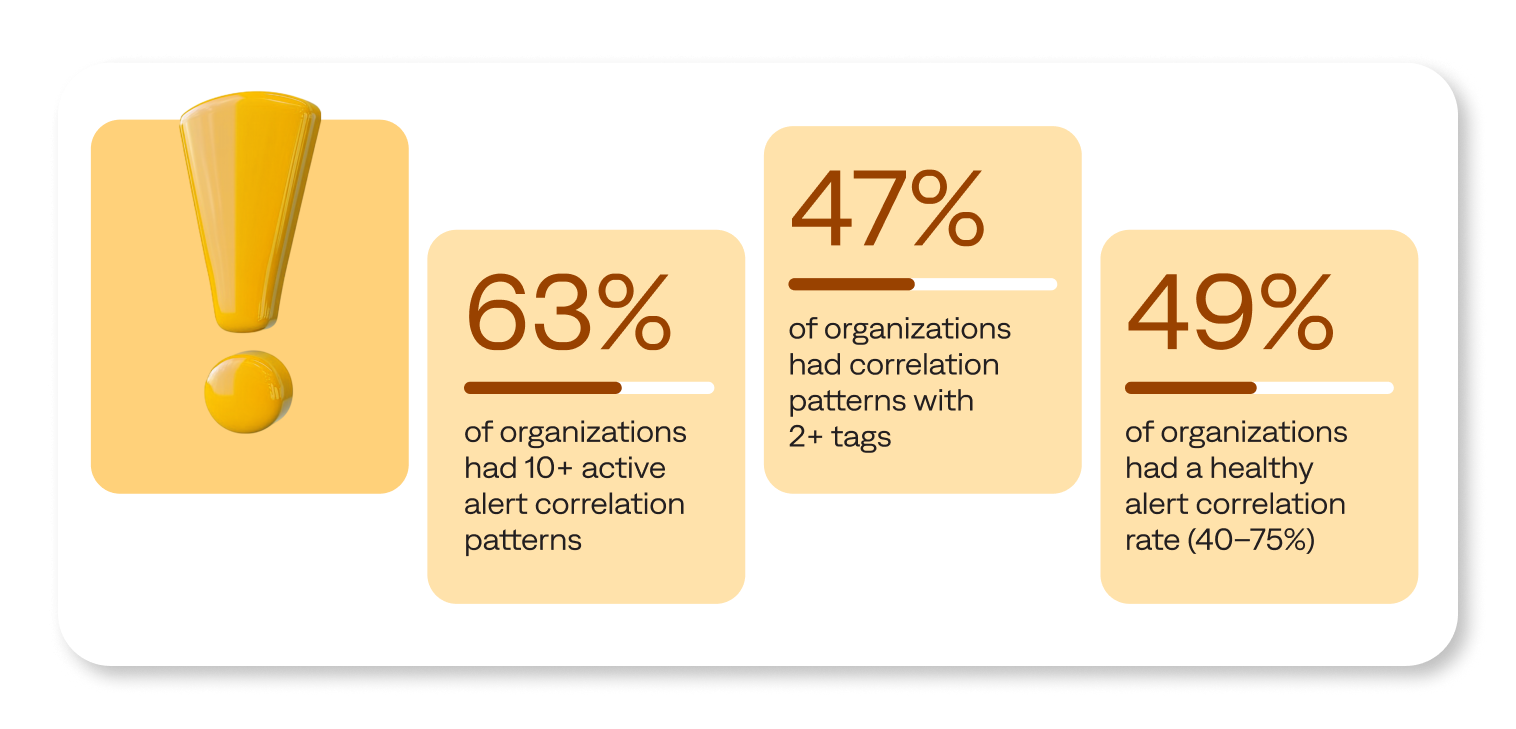
A robust observability practice is essential, but it’s only one component of a thoroughly modern event management and incident response strategy. Equipping your teams with high-quality, contextual alerts allows operators to triage, investigate, and resolve incidents as efficiently and effectively as possible.
With AI-powered alert correlation, you can instantaneously give your operators access to the most relevant, full-context incident data, providing a greater understanding of incidents within seconds. Agentic AI can identify incident titles, descriptions, and probable root cause within seconds. Ops teams can review and verify auto-generated incident diagnoses immediately, understand causality and impact quickly, and shorten resolution time dramatically.
Get more insights about the case for observability tool consolidation
Our research confirms what many IT leaders already suspect- that more monitoring coverage doesn’t automatically mean more actionability. Enterprises are investing heavily in observability, but without context, correlation, and enrichment, the signal gets lost.
Even the most effective platforms have room for improvement. While observability tools provide system visibility by collecting metrics, events, logs, and traces, they create a massive volume of noise, making it difficult for your teams to take action. This signals that even the strongest platforms have room to grow, and the observability industry is still evolving toward optimal performance at scale. These results highlight a clear opportunity for IT leaders to consolidate around high-performing tools, decommission low-value ones, and use enriched event data to guide smarter investments.
That’s where BigPanda comes in. While there is no magic bullet to stop tool sprawl, BigPanda helps IT organizations deliver an unbiased view of each observability tool’s impact on the incident management process.
Agentic IT operations add value to observability tools by automatically filtering out unnecessary noise and highlighting critical, actionable alerts. The BigPanda agentic IT operations platform ingests alert data from observability and monitoring tools, normalizes it, and enriches it with operational, contextual, and topology data from available CMDBs. Our platform delivers accurate, up-to-date, real-time visibility into your applications, services, and infrastructure while reducing noise, correlating multi-source alerts, and enabling powerful workflow automations.
These are just a few of the findings from the research. Please view the full report for more insights.




