WHITE PAPER
Derisking IT Change Management with Agentic AI
Prevent incidents and reduce downtime through automated change risk mitigation

Executive summary
IT change management practice challenges
High volume of changes
Increased change-related risk
High rates of change-induced failure and outages
The cost of change-related incidents
Proactive change risk management
Benefits of using AI and automation for IT change management
Features checklist for IT change management tools
IT change management tool overview
Conclusion
Endnotes
References
Executive summary
Modern enterprises are deploying application, infrastructure, and configuration changes at unprecedented speed, and paying a steep price when those changes go wrong. Human-driven and automated changes are the leading causes of outages, incidents, and costly service disruptions. As digital ecosystems become increasingly complex, traditional change management practices, such as manual reviews, change advisory board (CAB) meetings, static questionnaires, and fragmented visibility, cannot keep pace. The result is mounting operational risk, wasted labor, and a widening reliability gap.
Research shows that change-related failures are pervasive across industries, often accounting for the majority of major incidents, and that outages now cost enterprises millions of dollars per hour. Meanwhile, teams are overwhelmed by opaque dependencies, inconsistent risk assessments, and the sheer volume of changes.
AI and automation offer a transformative path forward. By unifying operational, topological, and historical data into actionable context, AI-powered IT change management enables organizations to predict and prevent change-related incidents before they impact users. Advances in generative and agentic AI enable the analysis of unstructured data, the detection of patterns invisible to human reviewers, the scoring of change risk with consistency and clarity, and the automatic recommendation of mitigation steps.
Industry research reflects this shift. Organizations adopting AIOps report fewer outages, faster recovery times, and measurable improvements in operational efficiency. Investments in AI-assisted troubleshooting, root cause analysis, predictive analytics, and automated remediation continue to accelerate as teams seek proactive, scalable approaches to reliability.
For enterprises struggling with rising change volume, limited visibility, and the growing cost of downtime, AI-driven change risk management provides a modern foundation for stability—strengthening governance, reducing manual toil, and enabling teams to innovate with confidence.
This white paper examines why change management is no longer human-scale and why organizations must rethink the way they evaluate and govern change. It outlines the challenges inherent in traditional change processes, the benefits of applying AI and automation, the key features to look for in a modern solution, and how available tools compare.
IT change management practice challenges
Human-driven change remains a leading cause of outages and incidents, pulling teams away from strategic work and toward repetitive firefighting.
Determining the potential blast radius of a change prior to its implementation is notoriously difficult because change owners frequently lack the necessary visibility. So, when a change causes problems, they don’t immediately associate the observed impacts with the change, which delays diagnosis, rollbacks, remediation, and restoration of service.
Without predictive data or actionable guidance, organizations can’t anticipate and prevent change-related failures. These failures occur when intentional modifications—such as software deployments, patches, network reconfigurations, or infrastructure updates—introduce instability or unexpected interactions across systems. These issues can quickly cascade and become difficult to contain, often resulting in rollbacks and service disruptions that impact customers and the business’s bottom line.
This section examines how these constraints manifest in the volume of changes, change-related risk, change-induced outages, incident costs, and operational costs.
High volume of changes
Modern software delivery practices are accelerating the pace of change across digital environments. Agile and DevOps methodologies promote smaller, more frequent releases, which shorten innovation cycles but also increase operational pressure.
Recent industry research highlights the rapid increase in the velocity of change. The 2025 State of AI-Assisted Software Development report, published by the DevOps Research and Assessment (DORA) team at Google Cloud, defines deployment frequency as the number of deployments made over a given period. The report found that 76% of survey respondents deploy at least once per month, including 45% deploying weekly and 23% deploying daily.1
Similarly, the 2025 State of ServiceNow Operations report found that half of organizations deploy code to production daily or weekly, with 35% releasing updates weekly and 5% deploying daily.2 For large enterprises, the cumulative volume is often substantial. For example, a global financial institution reported executing roughly 50,000 IT changes in a single year.
As deployment frequency rises, organizations relying on human-led change reviews must constantly navigate the tradeoff between speed and due diligence.
Increased change-related risk
As the change volume expands, so does the risk. The change velocity has increased, but the processes to manage change risk haven’t scaled accordingly; the change management processes are still manual, human-driven, and prone to many human failures. The teams reviewing changes often lack the necessary context and technical understanding, making it difficult for them to assess risk and frequently leading to hasty decisions under pressure.
Observability data shows that organizations increasingly track change metrics to manage this risk. The 2024 Observability Forecast report found that 34% of respondents reported using DORA metrics, including deployment frequency, change failure rate, and time to restore service, to reduce downtime.3
Likewise, in the AIOps-Powered IT Service: Insight for Action report, 27% cited DevOps release frequency and change-failure rate as top metrics for measuring AIOps effectiveness.4
High rates of change-induced failure and outages
Despite these efforts, many organizations still experience high rates of change-induced failure. Human-executed and automated changes remain among the leading contributors to IT outages.
The Annual Outage Analysis 2023 report found that changes were the most common cause of failures at the network, infrastructure, and software layers, resulting in outages. These failures proved true across configuration changes, upgrades, patches, and similar modifications, which can introduce instability that quickly propagates across distributed systems.5
![]() Human-executed and automated changes remain among the leading contributors to IT outages.
Human-executed and automated changes remain among the leading contributors to IT outages.
According to the 2025 State of AI-Assisted Software Development report, nearly two-thirds (64%) of organizations experienced a change failure rate of at least 8%, including 38% with failure rates of 16% or higher.6 To put this into perspective, if an organization deploys 50,000 changes per year (as in the earlier example), an 8% change failure rate translates to 4,000 incidents caused by changes each year.
Rework rates were also significant, with 74% of respondents reporting a rework rate of 8% or more, and nearly one-quarter (23%) reporting rework levels of 32% or higher. These failures carry operational consequences: 43% of organizations indicated it takes at least a day to restore service after a failed change, including 15% who require a week or more to recover.7
Additional research reinforces this pattern. The “Configuration Change Trouble and Other 2024 Outage Trends” article highlighted configuration changes as a primary driver of 2024 outages, a trend intensified by continuous integration/continuous delivery (CI/CD) practices, accelerated rollout cycles, and distributed architectures.8 The 2024 and 2025 Observability Forecast reports provide further quantification: Over a quarter (26%–28%) of respondents identified either deploying software changes or someone making a change to the environment as the primary cause of outages in their organizations.9 10
Anecdotal evidence mirrors these findings. One major insurer reported that approximately half of its incidents were related to changes. A global financial services organization noted that 18% of its major incidents were caused by change, with nearly two-thirds classified as low risk, indicating systemic challenges in evaluating change and classifying risk.
Across industries, a clear trend emerges, indicating that as organizations accelerate the pace of change, the frequency, severity, and operational cost of change-related failures increase. Without scalable, intelligent systems to evaluate and govern these changes, human teams, no matter how experienced, struggle to keep pace with modern digital complexity.
The cost of change-related incidents
Outages, including those caused by changes, remain among the most financially damaging disruptions an enterprise can face. As digital complexity increases and deployment velocity accelerates, the cost of a single misconfigured release or faulty update has risen sharply.
Industry research confirms the high stakes involved. The IT Outages: 2024 Costs and Containment report estimated an average cost of US$14,056 per minute of unplanned downtime, a 9% increase year-over-year, equivalent to US$843,360 per hour for the typical enterprise. For organizations with more than 10,000 employees, the estimated hourly cost rises to US$1.425 million.11
Similarly, the Annual Outage Analysis 2025 report found that 90% of organizations incur over US$300,000 per hour of downtime, with 41% citing costs between US$1 million and US$5 million per hour. Over half (54%) reported that their most recent outage exceeded US$100,000, and one in five experienced a loss above US$1 million.12
In the 2025 Observability Forecast report, respondents reported a median cost of US$2 million per hour for high-impact outages, up from US$1.9 million in 2024.13 14
These aggregate figures are reflected in recent, high-profile outages directly caused by software or configuration changes. Each illustrates how a single faulty update can produce outsized financial and operational consequences across industries:
- CrowdStrike outage on July 19, 2024: A faulty content update pushed to Microsoft Windows systems caused widespread blue screen of death (BSOD) failures, cascading across various industries, including airlines, banks, retailers, hospitals, and government agencies. Parametrix, a cloud monitoring and modeling provider and insurer, estimated that U.S. Fortune 500 firms would incur approximately US$5.4 billion in losses due to the outage.15 Delta Air Lines alone reported US$500–$550 million in costs from flight cancellations and recovery operations.16
- AWS outage on October 19–20, 2025: A faulty automated update to routing or DNS control-plane software propagated across multiple Amazon Web Services (AWS) regions, disrupting EC2, RDS, Lambda, networking, and dependent third-party services. The outage lasted over 15 hours and resulted in substantial service degradation across thousands of enterprise workloads. CyberCube estimated that the outage impacted approximately 70,000 organizations, including 2,000 large organizations, and projected a preliminary insured loss estimate of between US$38 million and US$581 million.17 Several major apps were affected, including Coinbase, Fortnite, Signal, Perplexity, Venmo, and Zoom.18
- Cloudflare outages on November 18 and December 5, 2025: In 2025, Cloudflare experienced several major change-related outages that disrupted large portions of the internet. On November 18, a database permissions change caused a bot management feature file to exceed memory limits in the Cloudflare proxy layer, resulting in a global outage that lasted over five hours and affected services, including ChatGPT, Spotify, X, Canva, Discord, Claude, and Figma, used by an estimated 2.4 billion monthly active users.19 20 Just weeks later, on December 5, a code error introduced during a security update briefly impacted roughly 28% of global HTTP traffic, taking major financial and consumer applications offline for about 25 minutes.21 The financial losses for the November outage alone were estimated to be in the billions for e-commerce, SaaS, and trading platforms, due to lost sales and service level agreement (SLA) credits.22
These incidents highlight a consistent pattern: Small changes can produce disproportionately large failures when released into complex, interconnected systems. Even routine configuration adjustments can trigger failures that ripple across global user bases and business ecosystems. As dependency chains grow longer and digital systems become more distributed, the financial and reputational risks associated with change-related incidents will continue to escalate.
![]() A single faulty update can produce outsized financial and operational consequences across industries.
A single faulty update can produce outsized financial and operational consequences across industries.
As the frequency and velocity of change accelerate across digital environments, the pressure on IT and operational teams has reached an unsustainable level. Organizations must deploy updates and improvements faster than ever, yet the people and processes responsible for ensuring safety and stability are already overwhelmed.23 This tension exposes a widening operational gap: Systems built for a slower, more predictable era constrain teams expected to move with agility.
This misalignment is especially visible between distributed engineering and development teams and centralized IT operations (ITOps). While developers are incentivized to ship features rapidly, IT teams often tighten controls to prevent outages. The result is friction and circumvention; developers, faced with bottlenecks, may bypass risk-mitigation processes entirely and push unvetted changes into production, introducing preventable risk.
Without automated safeguards or standardized evaluation criteria, change safety becomes dependent on tribal knowledge and manual reviews. Teams lack visibility into the actual impact or risk of a change, forcing them to rely on guesswork, experience, or static questionnaires that fail to incorporate historical incidents, service dependencies, or the reliability of the teams making the change. Non-standard or automated changes often require disproportionate human effort to validate, consuming valuable time and still producing inconsistent outcomes.
For example, Albert Wong, Senior Cloud Engineer at Cardinal Health, recalled in a webinar how they “used to export everything from ServiceNow into [Microsoft] Excel” and how “it took hours and relied heavily on manual judgment.”24
![]() Without automated safeguards or standardized evaluation criteria, change safety becomes dependent on tribal knowledge and manual reviews. Teams lack visibility into the actual impact or risk of a change, forcing them to rely on guesswork, experience, or static questionnaires that fail to incorporate historical incidents, service dependencies, or the reliability of the teams making the change.
Without automated safeguards or standardized evaluation criteria, change safety becomes dependent on tribal knowledge and manual reviews. Teams lack visibility into the actual impact or risk of a change, forcing them to rely on guesswork, experience, or static questionnaires that fail to incorporate historical incidents, service dependencies, or the reliability of the teams making the change.
As a result, enterprises over-invest in labor-intensive mechanisms such as CABs. These processes typically involve senior personnel and often consume 12–13 hours per week on preparation and review. In one large enterprise, CABs meet multiple times per day with dozens of participants. Even after deployment, organizations incur additional costs. For example, one enterprise reported that post-incident documentation alone can take 16 hours of staff time.
Yet despite this investment, CABs are fundamentally ineffective. Reviewers rarely have sufficient context to understand the risk profile of a change and often default to evaluating the perceived competence of the individual requesting approval. According to industry research, CABs often lack sufficient time and information to review every change thoroughly. Attempting to do so slows progress and increases risk; bypassing them creates blind spots and introduces untracked changes. Either path leads to increased operational stress and a higher incidence of change-related outages.25
As volumes increase and manual review processes hit capacity, teams inevitably work around the system. Risk levels may be intentionally inflated or deflated, depending on the level of visibility a team wants. In many organizations, teams describe change risk assessment as “guesswork” or “a mess.”
The underlying issue is clear: Modern change risk analysis can no longer be managed at a human scale. Industry research indicates that human-only approaches can no longer keep pace with the speed and complexity of digital change.26 Without intelligent, automated support for assessing, contextualizing, and mitigating change risk, organizations remain vulnerable to change-related incidents. In today’s environment, managing change without agentic AI is both inefficient and irresponsible.
Proactive change risk management
Proactive change risk management increasingly depends on AI and automation. Industry research recommends shifting work from humans to machines by automating frequent tasks, including standardized change policies and processes that follow best practices.27 To prevent change-related incidents, organizations need automated risk analysis and holistic impact assessments across the entire IT ecosystem.
Achieving proactive change risk management requires unifying vast amounts of sprawling, siloed internal and external data into clear, actionable context—something that wasn’t possible at scale until recently, thanks to advances in AI. Generative AI can now consume unstructured data to uncover hidden insights and patterns.28
According to the AIOps-Powered IT Service: Insight for Action report, about a third of the survey respondents indicated that untapped data sources—such as informal human knowledge (34%), incident communications (33%), historical data from previous IT service management (ITSM) tickets and resolutions (31%), and runbooks, knowledge base articles, standard operating procedures (SOPs), and after-action reviews (31%)—would help prevent incidents.29
![]() Achieving proactive change risk management requires unifying vast amounts of sprawling, siloed internal and external data into clear, actionable context—something that wasn’t possible at scale until recently, thanks to advances in AI.
Achieving proactive change risk management requires unifying vast amounts of sprawling, siloed internal and external data into clear, actionable context—something that wasn’t possible at scale until recently, thanks to advances in AI.
AI, and specifically AIOps, can identify misconfigurations across networks, cloud services, and applications. Teams can also use AI to detect and remediate individual errors within a specific cloud service, development silo, or application component.
AIOps adoption is accelerating. In the 2025 Observability Forecast report, nearly half (48%) of the survey respondents indicated that their strategy for the next 12–24 months includes increased investment in AIOps and machine learning. About a third expect the greatest improvements from forecasting and predictive analytics (32%) and AI-assisted remediation actions (31%).30
Similarly, the ServiceOps 2024: Automation and (Gen)AI-Powered IT Service and Operations report found that half (50%) of survey respondents view increased automation, AI, and AIOps as their top ITOps improvement goal for the next six to 18 months. Additionally, nearly a quarter (24%) identified better change management as a top ITSM/service-desk priority.31
In a webinar, Albert Wong, Senior Cloud Engineer at Cardinal Health, said, “Change management is vital […] being able to understand and assess the risk of a change, avoid change-related impacts, and quickly find failures caused by changes. […] The tool makes sure we pay attention and dig in before something causes an impact.”32
This section reviews the benefits of using AI and automation for proactive change management, highlights key features to look for, and provides an overview of available IT change management tools.
Benefits of using AI and automation for IT change management
AI brings effectively unlimited labor to change risk analysis. Work that would take a team of experts hours—reviewing historical incidents, evaluating dependencies, interpreting change plans, and assessing team reliability—can now be performed instantly and tirelessly by AI agents.
![]() AI brings effectively unlimited labor to change risk analysis. Work that would take a team of experts hours can now be performed instantly and tirelessly by AI agents.
AI brings effectively unlimited labor to change risk analysis. Work that would take a team of experts hours can now be performed instantly and tirelessly by AI agents.
Using AI and automation for proactive change risk management provides valuable business outcomes, including:
- Reduced manual labor and operational spend by eliminating repetitive, judgment-based review work, lowering manual overhead (blue dollars), and freeing senior staff from routine evaluation tasks.
- Fewer major incidents and significant cost avoidance by materially reducing outage frequency, severity, and related costs (teal dollars).
For example, the IT Outages: 2024 Costs and Containment report found that organizations leveraging AIOps experience fewer and shorter outages, with 30% of respondents reporting a decrease in outage frequency and cost after implementing proactive AIOps systems. An additional 43% cited predictive and proactive AIOps actions as the most valuable capabilities for their organization.33
Albert Wong, Senior Cloud Engineer at Cardinal Health, noted in a webinar that, “The [AI and automation] technology gives us a much more accurate, data-driven assessment of changes versus relying on human judgment. […] It has made us much more effective and accurate in implementing changes. […] It frees up change managers to be hyper-focused on what really matters. […] We’re using the technology to help drive better human behavior around change implementation.”34
Specifically, AI and automation can help organizations reduce risk, improve reliability, increase speed, scale operations, enhance operational efficiency, and support informed decision-making.
![]() Non-disruptive, non-displacing AI provides a safety net for existing change systems, delivering accuracy, consistency, and scale that human teams alone simply cannot achieve—and doing so with zero incremental human effort.
Non-disruptive, non-displacing AI provides a safety net for existing change systems, delivering accuracy, consistency, and scale that human teams alone simply cannot achieve—and doing so with zero incremental human effort.
Risk reduction and reliability
- Predict change risks, prevent incidents, and protect revenue. AI can automatically flag high-risk changes by analyzing historical incident data, change success/failure rates, affected configuration items, and organizational context. Predicting and preventing change-related failures helps reduce incidents, avoid escalations, preserve uptime, protect brand reputation, and support top- and bottom-line growth.
- Proactively identify change risks. Evaluating every proposed change against known risk factors, past incidents, and environment-specific patterns streamlines CAB reviews, reduces the need for rubber-stamping, and exposes hidden risks early before changes progress through the pipeline.
- Ensure consistent, bias-free change decisions. AI-driven change review and risk assessment provide teams with consistent, unbiased, high-quality feedback. It helps reduce or avoid conflicting feedback from different teammates.
Speed and scale
- Automate change analysis and approve changes faster. AI-generated change risk scores provide clarity and consistency, reducing friction between central IT and development teams and enabling faster, evidence-based change approvals.
- Provide scalable change governance. AI provides the visibility and preventive detection needed to manage risk at enterprise scale. Operations teams can identify reliability concerns before they affect customers, even as change volume and system complexity continue to grow.
- Implement clear guardrails for automation at scale. Automated change analysis and real-time feedback loops can help establish robust governance boundaries that support fast and agile delivery. By offloading analysis to AI, organizations free up strategic resources to focus on innovation, rather than manual review.
Operational efficiency and decision making
- Increase efficiency and productivity. With clear visibility into change risk, impact, and mitigation steps based on historical patterns, teams can avoid duplicated effort and reduce unplanned work. Engineers regain time for strategic initiatives instead of troubleshooting or rolling back failed changes.
- Facilitate innovation and improve the customer experience. As AI reduces change-related incidents, teams can focus on delivering new features and enhancements. Fewer service disruptions directly translate to more reliable, high-quality customer experiences.
- Empower responders and change managers with actionable context. AI can provide clear reasoning and practical, step-by-step recommendations for resolving issues at scale. This guidance improves triage, prioritization, and service reliability, especially during high-pressure incident windows.
- Deliver clear insights for decision-makers. Dashboards and analytics can help uncover patterns across changes, recurring issues, and incident context, enabling leaders to track performance, measure progress, and identify opportunities for improvement.
In short, non-disruptive, non-displacing AI provides a safety net for existing change systems, delivering accuracy, consistency, and scale that human teams alone simply cannot achieve—and doing so with zero incremental human effort.
Features checklist for IT change management tools
Many change management best practices and features are necessary to enable proactive, AI-driven change risk management. When evaluating IT change management tools, organizations must look for key features in several categories, including change process management, change risk assessment, change management metrics, and change management administration or setup.
Change process management features
Many ITSM tools include change process management features, including:
- Change request template creation: Design and manage standardized templates that ensure all change requests capture consistent, required information.
- CAB scheduling/management: Organize, schedule, and facilitate CAB meetings, including managing attendees, creating agendas, and transcribing meeting notes.
- Change scheduling: Plan change implementations on a calendar, taking into account blackout windows, maintenance periods, and resource availability.
Change risk assessment features
The number, type, and quality of change risk assessment features offered by existing IT change management tools vary widely. Organizations should ensure that their tool uses AI-powered change risk intelligence features that enable their IT teams to predict and prevent change-related incidents, thereby improving overall service reliability. Key change risk assessment features include:
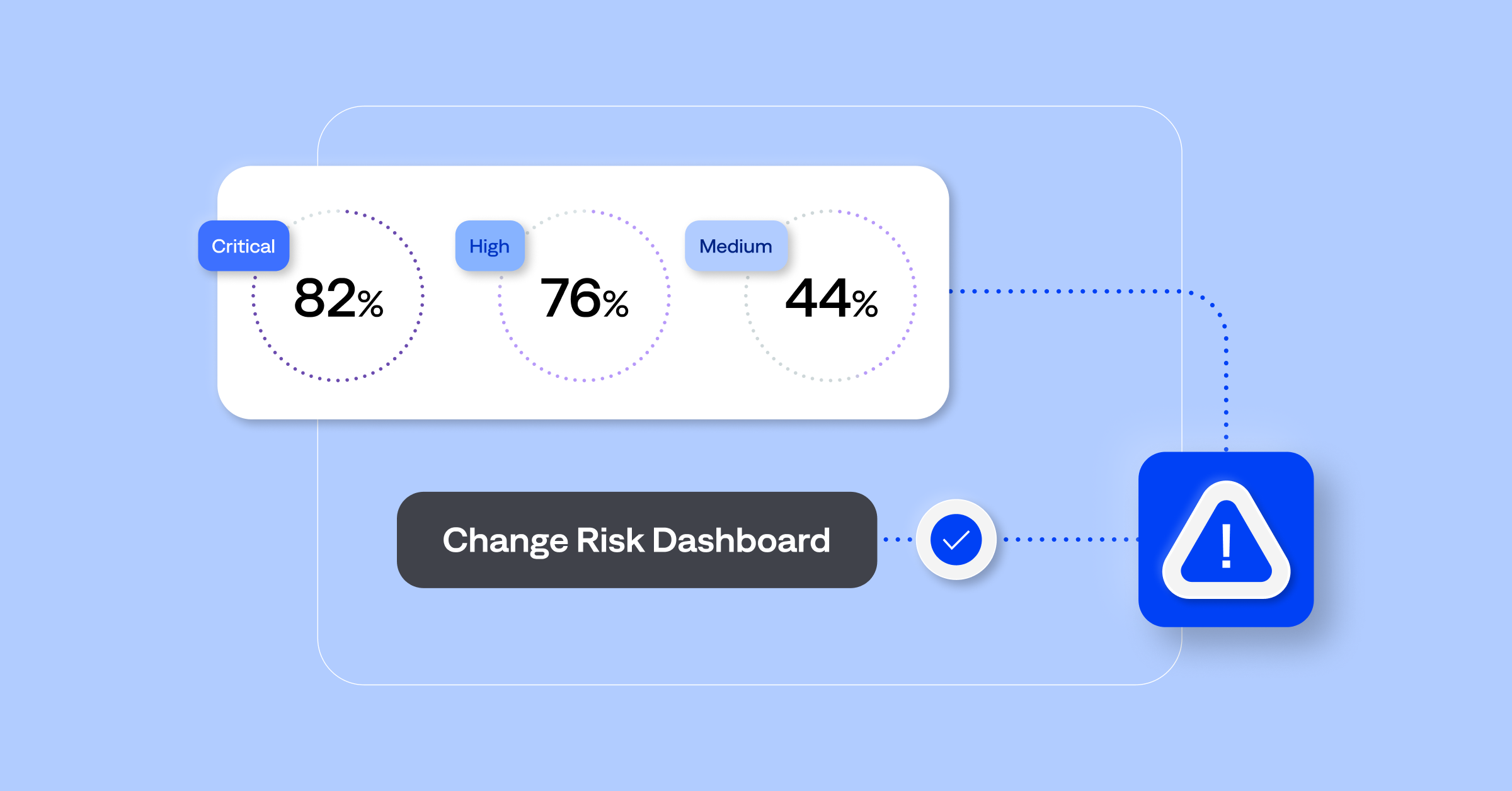
- Change risk dashboard: View risk levels, indicators, and trends for upcoming or in-flight changes in a unified dashboard, enabling operations teams to assess risk quickly.
- Change risk detection: Automatically identify potential risk factors, such as historical failures, conflicting changes, or missing approvals, within a change request based on ITSM data, non-ITSM data, or a combination of both.
- Automated change risk analysis (risk score or rating): Estimate the likelihood of change impact or failure with an AI-generated numeric or categorical overall risk score for each change based on predefined criteria, machine learning, or rules. AI can automatically evaluate every proposed change, incorporating known risk factors, past incidents, and environment-specific patterns. For the most accurate risk score, enterprises should look for a tool that addresses all five change risk factors:
- Historical incident risk estimates the likelihood of causing an incident based on historically similar changes that caused incidents.
- Implementation risk assesses the quality of the documented change plan, the complexity of implementation, and the nature of the change.
- Individual and team risk assess the calculated experience level and reliability of the individual or team performing the change.
- Organization-specific risk provides guidelines or criteria for evaluating risks specific to the organization.
- Topological impact risk identifies which parts of the environment will be affected and the degree of their criticality.
- Change risk reasoning: Understand the rationale behind why a change was rated as high or low risk, including the data inputs, logic, and contributing factors behind the score. It can be either AI-generated or manually generated. To reduce manual labor, organizations should look for a tool that uses AI to generate the reasoning.
- Change impact assessments: Evaluate the potential technical, service, or business effects of a proposed change, including dependencies and affected systems, based on ITSM data, non-ITSM data, or a combination of both. Ideally, the tool should be able to read attachments, which change submitters commonly include.
- Change risk mitigation recommendations: Provide teams with AI-generated, clear, actionable mitigation steps for each change request that teams can use to lower the risk of a proposed change, such as timing adjustments, extra testing, or additional approvals. Some tools offer generic recommendations only, while others provide both generic and specific mitigation steps. Ideally, the tool should provide and leverage both ITSM and non-ITSM data to provide mitigation steps specific to the organization and environment.
- Change conflict detection (change deconfliction): Automatically identify scheduling or resource conflicts between planned changes that may affect the same systems, windows, or teams. Ideally, the tool should be able to ingest ITSM data (such as changes, CIs, services, owners, and schedules), compare real-time context (such as change overlap, active incidents, and recent CI change failures), and then use agentic reasoning to interpret the combined dataset, even when the data is incomplete or non-standard.

Change management metrics
Visualizing change management data helps drive continuous operational improvement. The tool’s change risk analytics dashboard should include aggregated insights into risk patterns over time, including trends, distributions, and change-related outcomes. These insights enable decision-makers to gain insights into their change risk program, including:
- Change risk posture: Assess the organization’s collective change risk level, based on current pipeline, historical performance, and systemic risk factors.
- Change trend identification: Surface patterns in change activity, such as rising failure rates, recurring risky categories, or seasonal risk fluctuations.
- Team change success rate: Measure how often a specific team’s changes are implemented without causing incidents or requiring remediation.
- Change success/failure rates: View the percentage of changes that achieve their intended outcome versus those that result in issues, rollbacks, or incidents.
- Change prediction accuracy: See how often automated risk or impact predictions correctly align with the actual outcomes of implemented changes (false negatives and positives).
- Severity of incidents caused by changes: Understand how incident impact levels, such as downtime, service degradation, or customer effect, are directly attributable to implemented changes.
- Change risk distribution: View a breakdown of change requests by risk level (low, medium, high), category, team, or service.

Change management administration/setup features
Teams should be able to integrate with various change feeds, customize change risk category weightings, customize change-related push notifications to meet the needs of the organization, team, or individual, as well as post change results to the ITSM record:
- Integrations with change feeds (change source): Collect and normalize change data from various change feeds, such as CI/CD pipelines, other change management or ITSM tools, auditing systems, and orchestration tools. Ideally, it would include both standard and custom change source integrations. Connecting each change feed provides operations teams with deeper insights into the system changes that may be triggering system events and outages.
- Customizable change risk profiles: Create multiple, separate change risk configurations for different teams and business units within the organization. Customizable profiles are helpful for organizations that have teams that use different change risk evaluation criteria.
- Customizable change risk category weightings: Enable teams to define the relative importance of different risk factors when calculating overall change risk. Most tools offer default or out-of-the-box weightings, with either a native or non-native customization option.
- Customizable, real-time change-related push notifications: Enable teams to stay on top of high-risk changes and quickly mitigate them with automated alerts that notify users of change-related events, such as risk updates, conflicts, and scheduling changes, based on configurable rules. Notification options may include chat, email, in-product, SMS, or a combination of these four types of electronic collaboration.
- Posting change risk results to the ITSM record: Enable teams to view risk assessments in their ITSM system. An integration should automatically add risk scores, reasoning, or related insights directly into change tickets within an ITSM platform.

IT change management tool overview
The change management solutions available today are often bundled with ITSM tools. These tools primarily focus on the existing change processes, such as creating change request templates, scheduling changes, or identifying risky changes based on organizational information. Additionally, these tools are limited to the context within the ITSM tool.
ITSM tools are designed to document existing, human-judgment-based processes. Therefore, they don’t benefit from the large corpus of historical, topological, and other organizational data that could help evaluate a change’s risk. In addition, ITSM tools use a primarily walled garden approach instead of a holistic or agnostic approach, which results in data limitations.
The BigPanda agentic ITOps platform, on the other hand, is a data-agnostic solution. It includes BigPanda AI Incident Prevention, which offers enterprises a new approach to IT change management, focusing on the early detection and mitigation of high-risk changes. Its change risk management feature uses generative AI to analyze data from various operational and external sources, predict potential problems, and enable teams to implement solutions proactively. It’s the only change management solution capable of running detection at this scale because it has access to many tools and data sources. The data and context are unified in the BigPanda IT Knowledge Graph, enabling a more accurate risk analysis and impact assessment.
![]() ITSM tools are designed to document existing, human-judgment-based processes. Therefore, they don’t benefit from the large corpus of historical, topological, and other organizational data that could help evaluate a change’s risk. In addition, ITSM tools use a primarily walled garden approach instead of a holistic or agnostic approach, which results in data limitations.
ITSM tools are designed to document existing, human-judgment-based processes. Therefore, they don’t benefit from the large corpus of historical, topological, and other organizational data that could help evaluate a change’s risk. In addition, ITSM tools use a primarily walled garden approach instead of a holistic or agnostic approach, which results in data limitations.
What BigPanda does is fundamentally different from and additive to other ITSM solutions. Stacking BigPanda AI Incident Prevention alongside a traditional ITSM tool provides the best of both worlds. It’s not about replacing an existing ITSM tool; it’s about adding new functionality to the toolbox, so they work together more effectively. To that end, it includes standard inbound change source integrations with ITSM tools and other change feed sources, as well as standard outbound ITSM integrations. Teams can also configure custom integrations.
As Albert Wong, Senior Cloud Engineer at Cardinal Health, noted in a webinar, “BigPanda now automatically evaluates and identifies change controls that need deeper review. […] It increases awareness across the organization.”35
The following table shows an overview of the change-related features available for BigPanda AI Incident Prevention:
| Category | Feature |
BigPanda AI Incident Prevention36 37 38 |
| Change process management | Change request template creation | |
| CAB scheduling/management | ||
| Change scheduling | ||
| Change risk assessment | Change risk dashboard | |
| Change risk detection |
based on ITSM and non-ITSM data |
|
| Automated change risk analysis (risk score or rating) |
historical incident implementation individual/team org-specific topological |
|
| Change risk reasoning |
AI-generated |
|
| Change impact assessments |
based on ITSM and non-ITSM data |
|
| Change risk mitigation recommendations |
generic and specific |
|
| Change conflict detection |
based on changes, active incidents, and recent CI failures |
|
| Change management metrics | Change risk analytics dashboard | |
| Change risk posture | ||
| Change trend identification | ||
| Team change success rate | ||
| Change success/failure rates | ||
| Change prediction accuracy | ||
| Severity of incidents caused by changes | ||
| Change risk distribution | ||
| Change management administration/setup | Integrations with change feeds (change source) |
standard and custom |
| Customizable change risk profiles | ||
| Change risk category weightings |
default and native customization |
|
| Customizable, real-time push notifications |
chat in-product |
|
| Posting change risk results to ITSM records | ||
| BigPanda AI Incident Prevention change-related features by category | ||
Conclusion
Enterprise IT environments have reached a level of complexity where traditional, human-centered change management practices can no longer ensure reliability. Manual reviews, decentralized context, and inconsistent judgment introduce unacceptable levels of risk, especially as organizations accelerate the pace of digital delivery. As this white paper demonstrates, change remains one of the most common and costly sources of incidents. Outages triggered by misconfigurations, faulty updates, or missed dependencies can cascade across global systems, resulting in millions of dollars in losses and significant reputational harm.
The data clearly show that managing change without AI is no longer viable. Modern environments require real-time analysis, holistic visibility, and predictive intelligence that exceed human cognitive capacity. Agentic and generative AI bring unlimited labor, automatic pattern detection, and consistent evaluation criteria, transforming IT change management from a reactive, manual burden into a proactive, automated discipline.
Organizations that adopt AI-driven change risk management gain multiple strategic advantages:
- Fewer incidents and outages, driven by predictive detection and early intervention.
- Reduced operational overhead, freeing teams from manual toil and CAB overload.
- Greater governance at scale, supported by continuous, objective monitoring.
- Improved customer experience, enabled by higher service reliability and fewer disruptions.
- Increased confidence in change, shifting teams from defensive review cycles to forward momentum.
As this paper has highlighted, industry leaders are already investing heavily in AIOps and automation to strengthen their resilience and reduce costly downtime. Vendors across the market offer varying levels of change management support, but only solutions that are data-agnostic, context-rich, and capable of agentic reasoning can deliver the depth and breadth of insight required to safely manage modern change.
The path forward is clear: Organizations must augment their existing ITSM processes with AI-driven insight and automation. The combination of strong process foundations and intelligent change risk analysis provides the guardrails necessary for safe, agile, and scalable innovation. In an era where even a single faulty update can produce global impact, proactive, AI-enabled change management is a strategic necessity. The first step is selecting the right IT change management solution.
Endnotes
1(DevOps Research and Assessment (DORA) 2025, 3)
2(xtype 2025, 4–5)
3(New Relic 2024, 33)
4(Enterprise Management Associates (EMA) November 2024, 5)
3(Uptime Institute 2023, 17)
6(DevOps Research and Assessment (DORA) 2025, 21)
7(DevOps Research and Assessment (DORA) 2025, 21)
8(Cisco ThousandEyes 2025)
8(New Relic 2024, 33)
9(New Relic 2025, 11)
10(Enterprise Management Associates (EMA) April 2024, 3–5)
11(Uptime Institute 2025, 2)
12(New Relic 2025, 10)
13(New Relic 2024, 41)
14(Investopedia July 24, 2024)
15(Investopedia July 31, 2024)
16(CRN 2025)
17(TechCrunch 2025)
18(Cloudflare November 2025)
19(Pinggy 2025)
20(Cloudflare December 2025)
21(Pinggy 2025)
22(Gartner®, ITSM Best Practices for Effective IT Change Management, 2024.)
23(BigPanda December 2025)
24(Gartner®,ITSM Best Practices for Effective IT Change Management, 2024.)
25(Gartner®,ITSM Best Practices for Effective IT Change Management, 2024.)
26(Gartner®,ITSM Best Practices for Effective IT Change Management, 2024.)
27(McKinsey & Company 2025)
28(Enterprise Management Associates (EMA) November 2024, 13)
29(New Relic 2025, 8 and 20)
30(Enterprise Management Associates (EMA) June 2024, 8–9)
31(BigPanda December 2025)
32(Enterprise Management Associates (EMA) November 2024, 9–10)
33(BigPanda December 2025)
34(BigPanda December 2025)
35(BigPanda, n.d.)
36(BigPanda August 2025)
37(BigPanda November 2025)
References
BigPanda. August 2025. “Configure AI Incident Prevention.”
https://docs.bigpanda.io/en/configure-ai-incident-prevention.html.
BigPanda. November 2025. “AI Incident Prevention Analytics and Dashboards.”
hhttps://docs.bigpanda.io/en/ai-incident-prevention-analytics-and-dashboards.html.
BigPanda. December 2025. “The Real Cost of IT Changes: Prevent up to $2M Revenue Loss With Agentic ITOps,” Webinar.
https://www.bigpanda.io/resource/real-cost-it-changes-agentic-itops/.
BigPanda. n.d. “AI Incident Prevention for IT change and problem management.” Accessed December 12, 2025.
https://www.bigpanda.io/our-product/ai-incident-prevention/.
Cisco ThousandEyes. 2025. “Configuration Change Trouble and Other 2024 Outage Trends.” Internet and Cloud Intelligence Blog, January 17, 2025.
https://www.thousandeyes.com/blog/internet-report-configuration-change-outages.
Cloudflare. November 2025. “Cloudflare outage on November 18, 2025.” The Cloudflare Blog.
https://blog.cloudflare.com/18-november-2025-outage/.
Cloudflare. December 2025. “Cloudflare outage on December 5, 2025.” The Cloudflare Blog.
https://blog.cloudflare.com/5-december-2025-outage/.
CRN. 2025. “Amazon’s Outage Root Cause, $581M Loss Potential And ‘Apology:’ 5 Key AWS Outage Takeaways.”
https://www.crn.com/news/cloud/2025/amazon-s-outage-root-cause-581m-loss-potential-and-apology-5-aws-outage-takeaways.
DevOps Research and Assessment (DORA). Sep 23, 2025. 2025 State of AI-Assisted Software Development. Seattle, Washington: Google Cloud.
https://services.google.com/fh/files/misc/2025_state_of_ai_assisted_software_development.pdf.
Enterprise Management Associates (EMA). November 2024. AIOps-Powered IT Service: Insight for Action. Redwood City, California: BigPanda.
https://www.bigpanda.io/ar-ema-aiops-itsm/.
Enterprise Management Associates (EMA). April 2024. IT Outages: 2024 Costs and Containment. Redwood City, California: BigPanda.
https://www.bigpanda.io/ar-ema-outage-cost-2024/.
Enterprise Management Associates (EMA). June 2024. ServiceOps 2024: Automation and (Gen)AI-Powered IT Service and Operations. Redwood City, California: BigPanda.
https://www.bigpanda.io/ar-ema-serviceops/.
Gartner®, ITSM Best Practices for Effective IT Change Management, Steve White, December 19, 2024.
Investopedia. July 31, 2024. “Delta CEO Says Outage Cost $500M, Leaving Airline ‘No Choice’ But to Seek Damages.”
https://www.investopedia.com/delta-ceo-says-tech-outage-cost-usd500m-crowdstrike-microsoft-8686599.
Investopedia. July 24, 2024. “CrowdStrike Tech Outage Could Cost Fortune 500 Companies $5.4 Billion.”
https://www.investopedia.com/crowdstrike-outage-to-cost-fortune-500-usd5-4-billion-8683162.
McKinsey & Company. 2025. “Reconfiguring work: Change management in the age of gen AI.” August 13, 2025.
https://www.mckinsey.com/capabilities/quantumblack/our-insights/reconfiguring-work-change-management-in-the-age-of-gen-ai.
New Relic. October 2024. 2024 Observability Forecast. San Francisco, California: New Relic, Inc.
https://newrelic.com/sites/default/files/2024-10/new-relic-2024-observability-forecast-report.pdf.
New Relic. October 2025. 2025 Observability Forecast. San Francisco, California: New Relic, Inc.
https://newrelic.com/sites/default/files/2025-09/new-relic-2025-observability-forecast-report.pdf.
Pinggy. 2025. “How Cloudflare Incident Affected 2.4 Billion Internet Users.”
https://pinggy.io/blog/cloudflare_outage_november_18_2025.
TechCrunch. 2025. “Amazon identifies the issue that broke much of the internet, says AWS is back to normal.”
https://techcrunch.com/2025/10/21/amazon-dns-outage-breaks-much-of-the-internet/.
Uptime Institute. May 6, 2025. Annual Outage Analysis 2025: Executive Summary. New York, New York: Uptime Institute, LLC.
https://uptimeinstitute.com/uptime_assets/d7c049ef5b02a6e0a15540a3e5cb8fbf742c7fa54a1af6caeaaab32b7c15d443-GA-2025-05-annual-outage-analysis.pdf.
Uptime Institute. March 9, 2023. Annual Outages Analysis 2023. New York, New York: Uptime Institute, LLC.
https://datacenter.uptimeinstitute.com/rs/711-RIA-145/images/AnnualOutageAnalysis2023.03092023.pdf.
xtype. 2025. Annual State of ServiceNow Operations. Covina, California: xtype.
https://assets.xtype.io/story/2025-state-of-servicenow-operations.
GARTNER® is a registered trademark and service mark of Gartner, Inc. and/or its affiliates in the U.S. and internationally. All rights reserved.
Gartner does not endorse any vendor, product, or service depicted in its research publications and does not advise technology users to select only those vendors with the highest ratings or other designation. Gartner research publications consist of the opinions of Gartner’s Research & Advisory organization and should not be construed as statements of fact. Gartner disclaims all warranties, expressed or implied, with respect to this research, including any warranties of merchantability or fitness for a particular purpose.
DEMO
BigPanda AI Incident Prevention