



How agentic IT operations lay the foundations for SRE success at scale


When something breaks in a modern digital service, customers feel it instantly. Pages stall, requests time out, and carts are abandoned, while frustration grows long before a root cause is identified. What the world never sees is the engineering effort required to keep these systems healthy in the first place. Site Reliability Engineers (SREs) carry that responsibility every day. They work within complex, distributed, and constantly evolving environments where even a minor change can have unexpected consequences.
The work is always on and essential. SREs protect the experience that customers rely on and accelerate the engineering velocity that companies need to grow.
Why traditional IT operations cannot keep up with SREs
As systems become more fragmented and the pressure to move faster accelerates, the traditional ITOps model begins to break down. SREs cannot keep up with the volume of signals, the number of tools, or the complexity of piecing together what is actually happening during an incident. This acceleration is why forward-looking enterprises are adopting agentic ITOps.
According to Gartner’s Innovation Insight for AI Augmented SRE, 60% of SREs will rely on AI agents to support routine incident and postmortem tasks over the coming years. This trend reflects the reality that manual approaches simply cannot scale to the level of complexity that modern systems now generate.
Agentic ITOps transforms how enterprises ensure reliable IT infrastructures. Instead of relying on manually gathering clues, correlating signals, and rebuilding timelines across dozens of disconnected systems, AI agents perform this work autonomously. They assemble the vital context that an SRE needs to begin solving the actual problem, instead of wasting precious minutes or hours figuring out the issue. This autonomy aligns with Google’s SRE books, which recommend eliminating as much repetitive, manual work as possible so engineers can focus on higher-value improvements.
Where SREs feel the pressure first
In enterprise IT environments, support becomes critical the moment a production service slows down. The top priority is achieving clarity—not alerts or conjecture. SREs need a connected understanding of what changed and where the issue might be.
SREs describe the initial moments of an incident as a search for meaning inside noise. A single problem may trigger hundreds or thousands of alerts. The work required to understand the relationships between those alerts is where most of the manual, repetitive toil lives.
This issue is extremely visible in the financial sector. At the New York Stock Exchange (NYSE), a single event could trigger thousands of alerts, often masking the critical, single underlying issue. Once BigPanda correlated those alerts automatically, operators no longer had to comb through more than a thousand signals to identify the root problem.
With the noise reduced and the underlying issue isolated, the team could focus on fixing the problem instead of searching for it. The NYSE’s story reflects the challenging reality that nearly every SRE faces: noise increases much more rapidly than anyone can manually interpret it.
Agentic ITOps allow SREs to focus on engineering, not manual toil
The gaming world follows a similar pattern. At Bungie, major releases generated overwhelming volumes of operational signals. Each surge required a fast and precise investigation to protect the gaming experience of millions of players. After adopting BigPanda, noise levels collapsed by 99%. As Senior SRE Adam Cravens explains, “BigPanda delivered actionable investigation items directly to operators”.
This change shifted the focus from signal chasing to meaningful engineering. It is the kind of result that SREs in any industry can appreciate. Once the noise is under control and incidents become clearer, SREs want time to focus on the engineering work that improves reliability. That work ranges from raising Service Level Indicator (SLI) and Service Level Objective (SLO) performance to eliminating recurring problems before they impact users. It includes reducing repetitive toil, enhancing the quality of change delivery, and supporting a culture where teams can examine issues without blame, allowing them to learn and improve.
These expectations shape what SREs consider real engineering progress. Meeting them enables teams to move beyond constant firefighting and invest more of their time in higher-value engineering work that strengthens reliability. This sets the stage for why an agentic ITOps platform becomes so effective in the next phase of the journey.
What an agentic ITOps platform enables for SREs
These points reveal a deeper pattern in how SREs experience operational work. The core work of an SRE happens in the critical moments when an incident occurs, and everything hinges on clarity. As responders investigate and gather the full picture, patterns quickly emerge, and theory turns into decisive action. The moment a team decides whether a change is safe, and the stability of a service depends on getting that decision right.

The BigPanda agentic ITOps platform is designed for these critical moments.
- At the moment an issue first emerges, AI Detection and Response reduces floods of alerts into a few clear incidents that provide complete situational awareness.
- During investigation, AI Incident Assistant automatically brings context, incident summaries, and collaboration together to align teams.
- AI Incident Prevention helps teams stay ahead of issues by analyzing recurring problems and highlighting change-related risks, enabling teams to address these before they affect users.
Underneath it all, the IT Knowledge Graph provides the data foundation that SREs rely on. It unifies data from monitoring, change, service desk, and historical incidents into a single operational model that reflects how systems behave in reality. New signals constantly enrich it, enabling the identification of patterns and creating an always-up-to-date and evolving map of relationships that would be impossible to maintain manually.
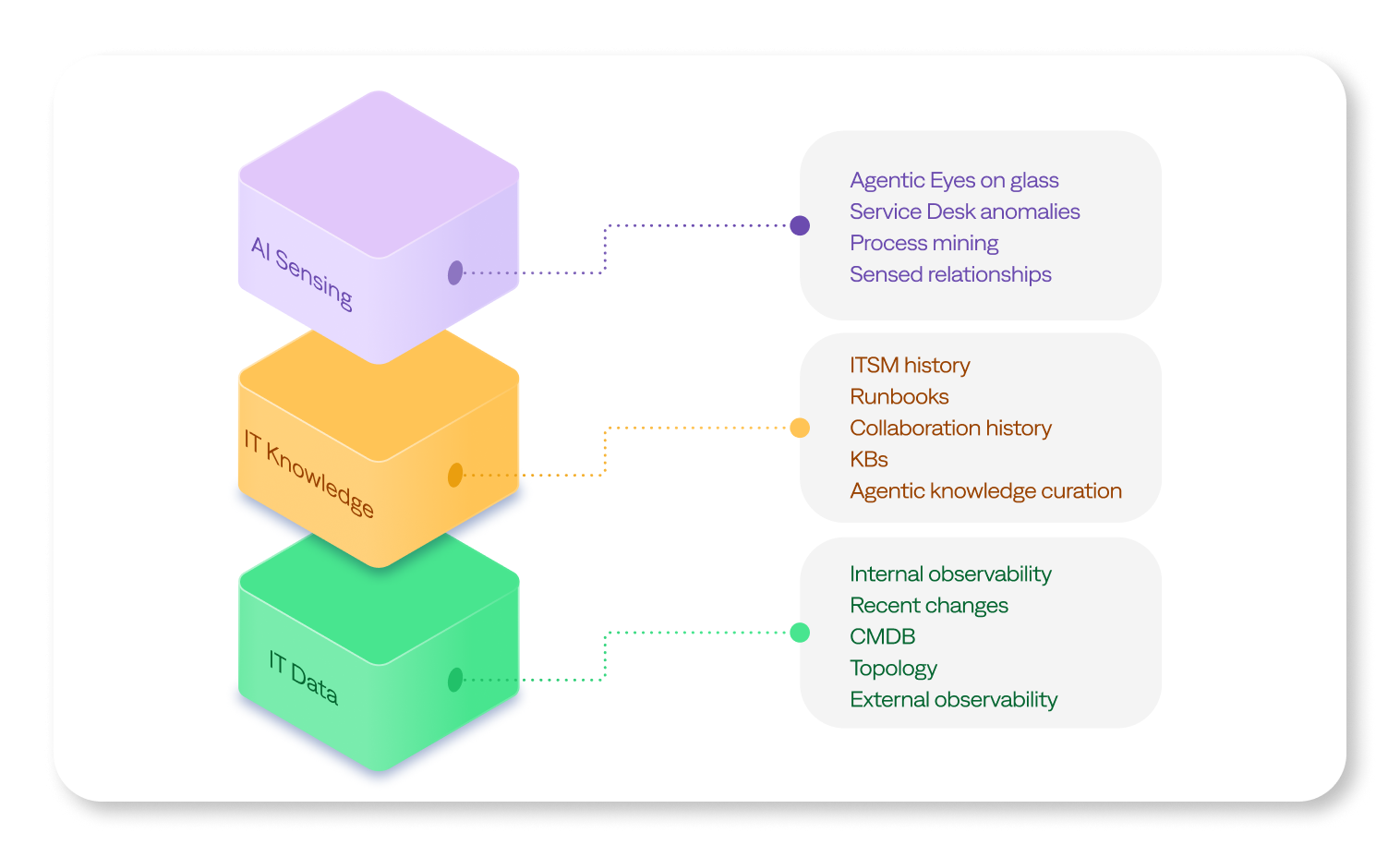
The IT Knowledge Graph enables BigPanda to explain why alerts belong together, what changes matter, and where patterns indicate deeper systemic issues. For SREs who value accuracy, traceability, and grounded reasoning, the IT Knowledge Graph is the differentiating layer that makes Agentic ITOps both powerful and trustworthy.
The integration of an agentic AI-powered platform and a continually evolving operational intelligence layer unlocks capabilities that traditional tools cannot provide. The system learns, adapts, reduces noise, and surfaces clear insights, thereby simplifying incident response. This integration provides SREs with clearer insights into each incident and its resolution path. Automated reasoning supports every part of the reliability workflow, including the complex moments where context matters most.
With a model built on centralized intelligence and decentralized execution, teams can move faster and more confidently without sacrificing governance or safety. This environment, which SREs have been asking for, involves automating manual, repetitive tasks, allowing engineers to focus on higher-value work of building resilient, scalable systems.
A new operating model for stable, reliable IT infrastructures
This new operating model addresses the realities of modern SRE work. Signals become narratives. Alerts become explanations. Raw data becomes connected insight. The system does the heavy lifting first, allowing engineers to focus on work that advances reliability, such as enhancing service behavior, resolving recurring issues, improving SLO performance, and creating automation that accelerates the entire organization.
To see how BigPanda can transform the reliability of your services, contact us to request a demo or receive a value assessment today.





