




BigPanda transforms IT major incident management with customizable AI workflows that eliminate coordination work and cut MTTR in half.
Incident management
The BigPanda AI Incident Assistant allows enterprises to respond to incidents at machine speed, dramatically improving operational efficiency and delivering exceptional service reliability.

Fragmented systems overwhelm SREs. Agentic ITOps uses AI agents to correlate signals fast, deliver context, and speed incident response.
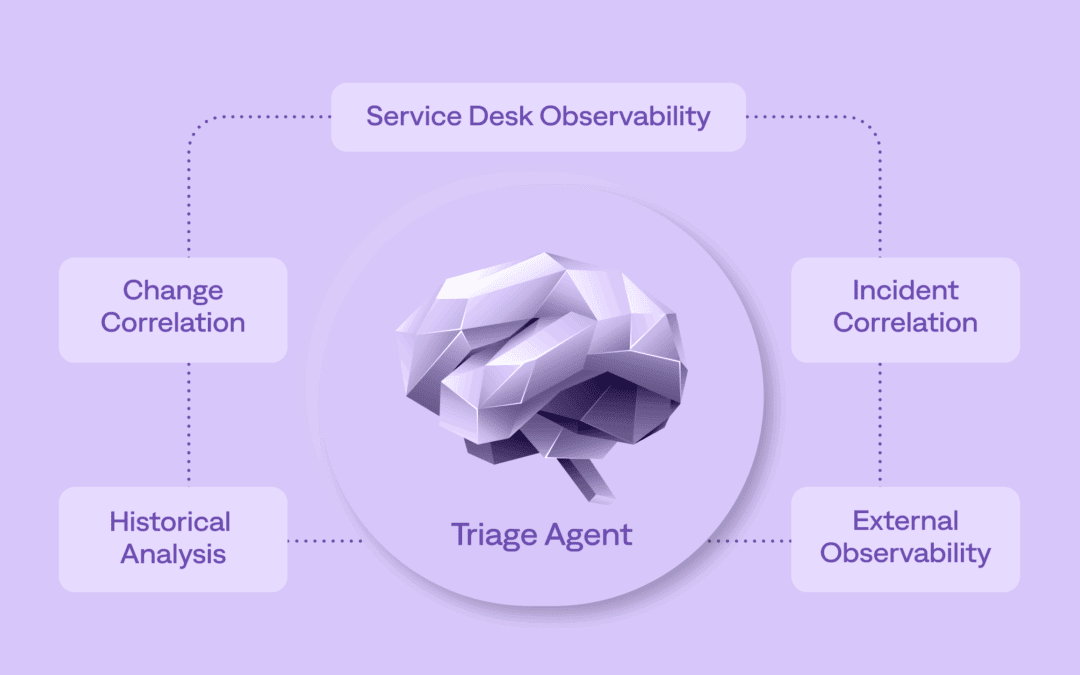
Triage Agent for ITOps gathers relevant context to automate investigation and improve triage, and reduces unnecessary escalations.

The recent Cloudflare outage served as a stark reminder of how fragile the global digital ecosystem can be due to a single point of failure. In a matter of minutes, thousands of websites that rely on Cloudflare’s CDN, from Fortune 500 brands to SaaS platforms and consumer apps, went offline for hours. The business impacts […]
When external providers fail—whether it was CrowdStrike outage last year, AWS outage last month, or the Cloudflare DNS outage yesterday—the symptoms inside your environment often look like internal issues: timeouts, login failures, API errors, service degradation, or sudden spikes in dependency-related alerts. It’s natural for teams to start searching through their own infrastructure first, but […]

Learn how to quantify the value of the BigPanda platform and read how customers justify their IT investment

Agentic ITOps from BigPanda deliver the promised value of AIOps by automating incident detection, triage, and resolution to cut costs and boost service reliability.

BigPanda was recognized in 10 Gartner Hype Cycles in 2025, showcasing leadership in Event Intelligence Solutions and IT operations innovation.

New ADR features help L1 teams achieve faster detection and utilize automation for more accurate diagnosis and triage.

BigPanda introduces agentic AI for ITOps. Our platform automates incident detection, triage, and resolution to cut costs and boost service reliability.

At BigPanda, HEART represents our core values, which guide how we work, collaborate, and serve our customers daily. HEART stands for Hunger, Extreme ownership, Active transparency, Relentless customer focus, and one Team (HEART). We strive to live by these principles in every project, meeting, and interaction. Each year, we celebrate the remarkable Pandas who embody […]
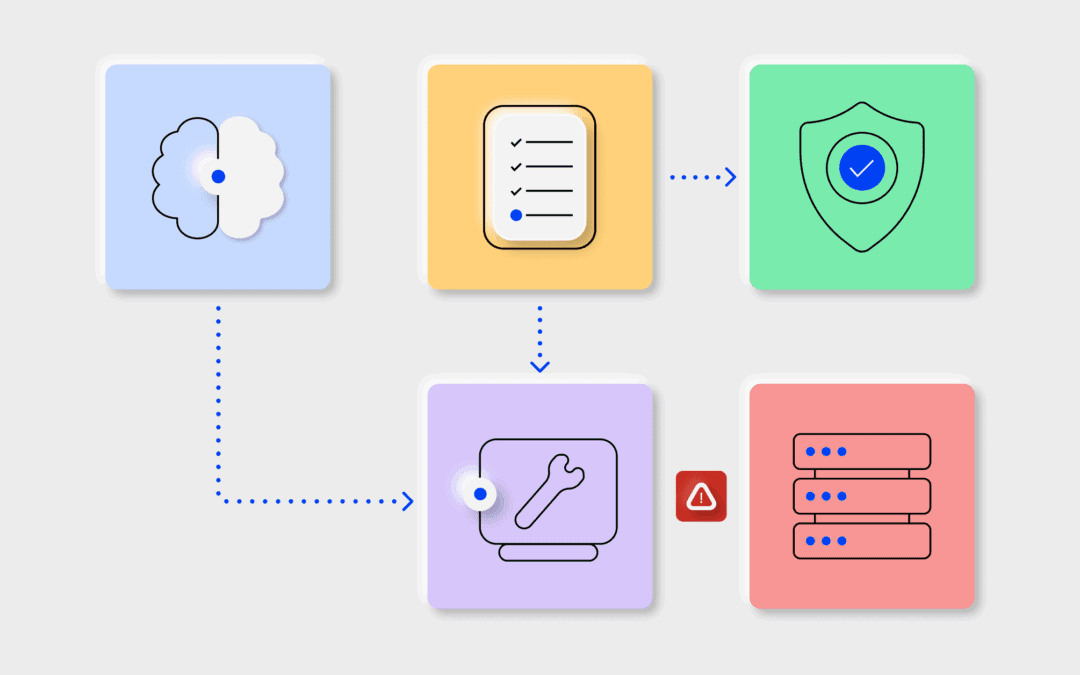
BigPanda AI Incident Prevention proactively mitigates IT change management risks. Designed to prevent incidents before they occur.

Learn what observability is and how it empowers IT teams to gain deep insights into system behavior and incident management.

Say goodbye to fractured, siloed data. GenAI can transform all unstructured data sources into usable fuel for agentic IT operations.
IT operations have reached a breaking point. Hybrid cloud and modern software architectures have led to unprecedented increases in the scale, complexity, and fragmentation of IT infrastructures. In their attempts to manage this complexity, enterprises invest billions into observability tools, IT Service Management (ITSM) platforms, and outsourced Managed Service Providers (MSPs). Despite these investments, enterprises […]

Fragmented tools, teams, and processes are more than an inconvenience in IT Operations. They are major bottlenecks that hinder collaboration, slow down incident resolution, and jeopardize customer experiences. In a recent webinar, Adam Blau, VP of Product Marketing at BigPanda, and Britton Starr, a Technical Account Manager, shared their insights into the operational chaos plaguing […]
Learn recommendations from Gartner® to reduce the impact of IT incidents on hybrid cloud environments with an AI-powered approach to ITSM.

BigPanda was named a Representative Vendor in the 2025 Gartner® Market Guide for Event Intelligence Solutions. BigPanda applies AI to augment, accelerate, and automate IT operations and incident management.

BigPanda was named as a Representative Vendor in the 2025 Gartner® Market Guide for Event Intelligence Solutions. BigPanda applies AI to augment, accelerate, and automate IT operations processes.
AI-Powered Event Management from BigPanda transforms siloed IT data into insights for faster detection and triage.

Eliminate recurring incidents by identifying trends and enabling proactive action to reduce downtime and improve IT efficiency.

With BigPanda AIOps, Sony accelerates incident response, improves efficiency, and enhances the work-life balance of its IT teams.

ITSM vs ITOM explained: Understand their roles, processes, tools, and how they complement each other to enhance IT performance.

Enhance ITOps and ITSM team efficiency across the entire incident lifecycle with BigPanda’s newest feature updates.

Learn how AIOps helps financial institutions improve operational resilience and incident management, gain visibility into their ICT, and maintain DORA compliance.

When your IT team is overwhelmed with tickets, dealing with shadow IT, and always putting out fires, it can feel frustrating. That’s where IT Service Management (ITSM) comes in. ITSM provides a plan to deliver reliable IT services. It helps teams focus on what matters most: achieving business success. It encompasses everything from handling incidents […]

BigPanda helps MSPs scale through technology and enhance and differentiate their service offerings to stay competitive.
Discover how to improve your ITIL incident management for swift issue resolution, minimal downtime, and continuous service improvement.

Over the next 10 years, enterprise CIOs will be judged primarily on how effectively they incorporate AI into ITOps and ITSM processes.
Learn how CIOs and ITOps teams can adapt their organizations to survive crisis-related challenges and be well-positioned for the long term.
Synthesize complex data with Ops Centric AI. Turn fragmented IT noise into high-quality, actionable insights for fast IT incident management.

AI-Powered Incident Management from BigPanda turns siloed data into situational awareness for faster IT incident investigation.

Uncover how AIOps can enhance your observability tools by automating tasks, streamlining alerts, and speeding up incident resolution.

BigPanda Advanced Insight uses AI to analyze complex data so responders can triage IT incidents faster and improve service reliability.

Learn how BigPanda AIOps unifies ITOps and incident management, delivering context for efficient resolutions and improved reliability.
A recent report from EMA research highlights the benefits of AIOps for IT operations (ITOps) and IT service management (ITSM) teams.
Generative AI is changing the game in IT services. Learn six ways IT teams benefit from GenAI for smoother, faster incident resolution.

Data integration improves ITOps with actionable insights to enable faster detection, better collaboration, and improved reliability.

Mean time to resolution (MTTR) is an important measure. It shows the average time needed to fix an application, service, or IT infrastructure component. Your MTTR affects customer satisfaction. You need to understand how it impacts the reliability and availability of your services. This knowledge helps you make informed decisions. It also enables operational efficiency […]

New features in BigPanda help ITOps and ITSM teams streamline incident response and ensure high service availability.

Operationalizing AI is essential to improve the efficiency of IT operations and remain effective in increasingly complex IT environments.

Create an effective incident response plan to protect service operations.

Build the skills you need to seamlessly integrate BigPanda with ServiceNow to improve incident management.

Five core incident response phases are part of a structured approach to managing and addressing disruptive IT events to protect your organization.

Runbooks bring order and organization to ITOps, offering concise instructions for teams to respond to critical incidents effectively.

Explore how to navigate generative AI challenges in IT operations and discover four key criteria for choosing the right AI copilot.
Transform future IT operations and incident management using AI copilots to enhance operational efficiency and speed incident resolution.

Tracking incident response metrics and key performance indicators (KPIs) is vital to minimizing service disruptions.

Six ways to use AIOps copilots to improve ITOps and incident management team efficiency, share knowledge, and deliver immediate value.

BigPanda customers shared their best practices and learnings from addressing the challenges brought on by the July 2024 global outage.

Discover effective strategies for alert noise reduction so you can focus on identifying and resolving critical incidents.
Infrastructure data trapped in silos — and a lack of operational context — creates delays and unnecessary stress for ITOps, observability, and ITSM teams.
Build a custom view in the BigPanda Incident Console to reduce MTTR and more effectively triage and resolve incidents.

Explore the benefits of data aggregation and gain insights into its operational framework to optimize your data management processes.

Surface the context you need within your event-management workflow using new updates in the BigPanda platform.

AI-powered copilots can troubleshoot active incidents in real time for ITOps and ITSM to identify cause, impact, and resolution steps.
BigPanda integrates with ServiceNow to give ITOps and ITSM teams the insights to proactively identify, respond to, and remediate incidents.
AIOps uses generative AI to create a unified view of IT incidents to help operators resolve outages faster and improve service availability.

On-demand: Normalize event payloads into a consistent taxonomy and enrich alerts with relevant context within the BigPanda platform.

Automating incident response for IT delivers multiple benefits. Save money and prevent incidents from escalating into outages.

The lines between ITSM and AIOps are blurring. Gartner Hype Cycle for ITSM, 2024 highlights this shift and changes in AIOps service delivery.
ServiceOps is a technology-enabled approach that unifies ITOps and ITSM teams to facilitate more effective incident management.
Event intelligence solutions or AIOps platforms? What does the new terminology from Gartner mean for you and your IT operations?

AIOps gives ITSM and ITOps teams a unified view of incidents and the IT environment, facilitating the key outcomes of ServiceOps.
Maximize your IT operations with proven AIOps use cases that drive efficiency and service reliability. Explore AI’s transformative potential today!

Empower ITOps and ITSM with context. Identify incident root causes based on recent changes for swift, accurate resolution.

BigPanda CIO Jason Walker joins financial services podcasts to talk about using AIOps and GenAI to improve IT incident management.

Unlock AIOps’ use case potential across technical, business, and operational realms. Streamline IT, boost efficiency, and drive innovation.

Discover the importance of IT incident management, its five stages, and how AIOps can optimize your organization’s IT event response.

Accomplish fast, reliable incident root-cause discovery with AIOps and significantly reduce mean time to resolution (MTTR) beyond manual capabilities.

Context is imperative for informed decision-making when facing obstacles like data fragmentation and disparate sources. AIOps delivers.

Outages can cost your organization up to $25,000 per minute. AIOps and automation can simplify, enhance, and shorten incident triage, leading to faster MTTR.

IT outages cost $14,056 per minute on average. What’s driving the increased costs? How can you use AIOps to reduce their frequency, duration, and impact?

BigPanda 24 brought together ITOps leaders from across industries to discuss the future of AIOps and IT operations. CEO Assaf Resnick shares his thoughts.
Reduce manual incident investigation, identify actionable insights, and speed resolution using relevant historical data from similar incidents.
Improve uptime and efficiency. With full-context IT operations management, you get the big picture of incidents every time, from every angle.

The BigPanda AI-powered copilot is the first to leverage all sources of human-generated, institutional knowledge for AI-powered incident response.

Our AIOps predictions focus on what’s next with generative AI, integration, automation, incident management, job roles, and market trends.

Learn how the BigPanda Root Cause Changes feature optimizes incident management by linking incidents with relevant changes to reduce resolution time greatly.

Improve your organization’s incident response capabilities with incident management software. Learn how to find the ideal solution for your needs.

Discover the new BigPanda Unified Console with timeline views, data exports, AI insights, collaboration, incident tags and environments, and UI.

Explore ServiceNow Incident Management: its importance, features, and benefits. Plus, learn how Autodesk reduced incidents by 69%.
Discover what IT incident tracking is and why it matters. Gain strategies to select the right tools and improve system reliability.

How does MTBF predict system reliability and uptime? Learn how it relates to MTTR and how to maximize it for seamless operations.

Workflow Automation and AIOps streamlines incident management and improves team collaboration. Learn how Abbott’s ITOps team overcame legacy system challenges with BigPanda.

BigPanda brings all your observability, topology, and change data into a single console. Read this best practices guide to learn how to get started.

The average cost of an IT outage is $12,900 per minute. Learn which steps IT Operations teams can take to minimize an outage’s impact.

Automating incident management helps more efficiently detect and resolve critical incidents. Learn more about the best practices for IT incident management.

Digitization of brick-and-mortar stores isn’t new—it’s evolving. Learn how ITOps teams can support this shift.

Here’s everything you need to know about CI/CD pipelines but were afraid to ask.

Part 1 of this series defines algorithmic alert correlation and how it works. The term “algorithmic” describes how data science applies machine learning techniques to solve alert storms, aka alert floods. There are two flavors of machine learning currently being applied to this problem: one is “black box” and the other, “open box”. BigPanda applies open […]